공모주 알리미 개발 후기 - 1부
작년부터 시작된 ‘동학 개미 운동’에 언제부터인가 필자도 주린이로써 동참을 하게 되었다. 최근에는 ‘공모주 청약’이라는 걸 알게 되었는데 따라 해보고 정신 차려보니 치킨 한 마리 정도의 수익을 얻는 기적이 일어났다. 공모주란 정해진 일자에 청약을 하고 배정을 받으면 해당 주식이 상장을 하기 전에 미리 살 수 있다는 ‘기회’로 이해했다. (주린이라 이해의 범위가 여기까지다…) 공모주 배정이 로또처럼 엄청난 큰 수익률을 가져다주는 건 아니지만 앞서 이야기 한 것처럼 언제 있을지 모르는 공모주 청약을 꼬박꼬박 챙겨서 하게 된다면 맛있는 치킨을 먹을 수 있겠다는 기대감이 부풀었다. (치킨은 역시 교촌 허니콤보…)

출처 : https://b-s-d.tistory.com/8
치킨이 머릿속에 맴도는 시간도 잠시. 필자의 머리를 스치는 하나의 생각. 그러면 공모주 청약은 언제 하는 거지? 청약하니까 준비하라고 누가 알려주면 좋을 텐데… 그러면서 이런저런 검색을 해보니 안드로이드 앱은 이미 있었고, IOS 앱은 없었다. 음? 그럼 이걸 내가 만들어보면 어떨까?
결론부터 말하자면, 텔레그램을 활용하여 자동화 공모주 알림봇을 만들게 되었다. 혹시 공모주에 관심이 있다면 필자가 만든 텔레그램 채널을 가입하는 것도 좋을 것 같다.
이번 글에서는 필자의 새로운 토이 프로젝트인 ‘공모주 알리미’를 만들게 된 배경과 설계, 그리고 개발부터 릴리즈까지에 대해 이야기를 해보고자 한다. 크게 아래의 목차로 이야기하게 될 것 같다.
- 1부 : 프로젝트 설계, 데이터 수집
- 2부 : 수집한 데이터 알림 발송
- 3부 : 서버 선정 및 릴리즈
자칫 너무 간단한데~, 이런 걸 굳이 왜 만들어?라는 시각이 있을 수 있겠지만 토이 프로젝트를 해야지 하고 마음을 먹었지만 막상 시작을 못하고 있는 어느 누군가에게는 도움이 될 내용인 것 같아서 꽤 자세히 정리를 하려 한다. 물론 이러한 정리는 필자 자신을 위해서가 더 크긴 하다.
프로젝트 설계
과거에 토이 프로젝트로 진행했던 기술블로그 구독 서비스의 경험을 되새기면서 처음부터 황소처럼 달려드는 것보단 충분에 충족을 더해 충만해질 때까지 고민을 오랫동안 해보기로 했다. (그래봤자 하루 정도…?^^) 우선 데이터를 어딘가에서 가져오고 가져온 데이터를 DB에 저장할 것인지 아니면 저장하지 않고 휘발성으로 조회후 버리는(?) 형태로 할 것인지를 고민해야 했다. 공모주라는 데이터의 특성상 한번 정해진 메타 데이터가 상황에 따라 변경이 될 수도 있다고 했기에(일정이 변경되거나 공모가가 변경되거나 등) DB에 저장을 하게 되면 이를 동기화(Sync) 하는 비용이 추가로 생길 것 같아서 알림을 보내기 직전에만 조회하고 버리는 형태를 생각했다.
그렇게 데이터를 조회했다면 이를 입맛에 맞게 가공하고서 사용자에게 알림을 줘야 한다. 알림을 발생시키는 방법은 매우 다양한데 뭔가 적은 비용으로 구성하고 싶었다. 즉, 알림을 받는 사용자가 10명, 100명, 1000명 이 되어도 (그렇게 될지는 모르겠지만;;) 내가 만든 서비스에서 알림 수신인이 늘어나는 경우를 고려하지 않아도 되었으면 했다. 그에 생각한 게 메신저 API. 그중에서도 텔레그램 API가 뭔가 이런 형식으로 딱일 것 같았기 때문이다. 결국 데이터를 메시지 형태에 맞춰 한 번만 발송하게 되면 1:N 형식(Broadcast)으로 텔레그램 채널을 구독하고 있는 사용자들에게 전송이 될 테니 안성맞춤이었다.
그럼 언제 어떤 정보를 알려주는 게 좋을까? 청약이 보통 오전에 시작하기 때문에 대략 매일 오전 9시에 관련 정보들을 보내주면 될 것 같았다. 3일 전에 청약을 시작하게 되니 미리 준비하라는 알림. 그리고 청약 날짜가 도래해서 잊지 말고 청약을 신청하라는 알림. 마지막으로 공모주가 상장을 하게 되는 알림. 이 세 가지 알림만 잘 챙긴다면 필자 같은 주린이들도 충분히 공모주 청약으로 치킨을 먹을 수 있을 거라 생각했다.
마지막으로 이 모든 내용을 개발한 어플리케이션을 어느 곳에 배포해야 하는지를 결정해야 했다. 항상 머릿속에는 있었지만 한 번도 안 해본 클라우드 Paas 인 heroku가 딱일 거라 생각했다. (실제로 해보지 않았던 지금까지는 그랬다…) 다들 토이 프로젝트 서버로 잘 활용한다는 소리를 들었고 가장 큰 장점은 ‘무료’라는 점에서 heroku를 선택하지 않을 수 없었다.
참, 이번 토이 프로젝트는 전부 ‘무료 서비스’를 이용하려 했다. 이 서비스가 비즈니스 모델이 있는 것도 아니고 그렇다고 후원을 받자니 턱없이 부족할 것만 같았다. (그럼에도 불구하고 후원 버튼은 달아둘 예정이긴 하다.)
데이터 수집
국내 공모주 데이터는 38커뮤니케이션 홈페이지에서 얻을 수 있었다. 꽤 자세하고 방대한 정보가 있었지만 필자가 원하는 데이터는 대부분 이 페이지에 나와 있었기에 이 페이지를 크롤링 하면 되겠구나 싶었다.
크롤링에 대한 법적인 문제는 깊게 고민하지 않았다. 해당 데이터를 가지고 영리목적으로 활용하는 것도 아니고 오히려 필자 같은 주린이들이 공모주에 더 참여할 수 있게 도와주는(?) 거라 생각이 든다. 혹시 문제가 된다는 연락이 오게 되면 서비스를 내릴 수도 있을 것 같다… ㅠ
이번엔 조금이라도 더 친숙한 Java + Spring 조합으로 만들게 되었다. 그러다 보니 크롤링을 위해서 오픈소스를 사용해야 했는데 jsoup와 crawler4j를 찾을 수 있었다. 조금만 더 검색해보면 대부분 jsoup를 사용하는 사람들이 많았고 마지막 업데이트 일자도 jsoup가 crawler4j보다 나름 최신이라 jsoup를 사용해서 크롤링을 하면 될 것 같았다.
우선 아래처럼 dependency를 추가해주고
dependencies {
implementation 'org.jsoup:jsoup:1.13.1'
}
jsoup을 이용하여 페이지를 읽어와보자.
Document document;
try {
document = Jsoup.connect("http://www.38.co.kr/html/fund/index.htm?o=k").get();
} catch (IOException e) {
logger.error(e);
}
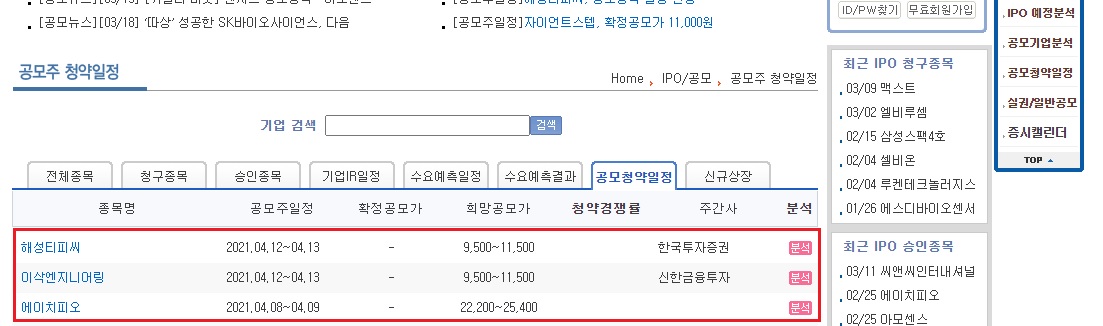
이후 css 문법으로 원하는 DOM을 선택해야 하는데 아쉽게도 원하는 Table에 id나 css가 없어 바로 선택하기 어려워서 한참을 헤매다 다행히 ‘summary’항목이 table마다 달라서 이를 활용해서 가져오게 된다. 이후 여러 tr 요소들을 순회하면서 데이터를 가져오자.
Elements trElements = document.select("table[summary='공모주 청약일정'] tr");
for (Element trElement : trElements) {
Elements tdElements = trElement.select('td');
// 헤더 제외
if (tdElements.size() != 7) {
continue;
}
tdElements.get(0).text(); // 공모주 이름
tdElements.get(2).text(); // 확정 공모가
// ...
}
마치며
여기까지 토이 프로젝트에 대해 다양한 시각으로 설계를 해보았고 공모주 관련 데이터를 크롤링을 통해 가져왔다. 다음 포스팅에서는 가져온 이 데이터를 텔레그램 API를 사용해서 텔레그램 채널에 보내는 걸 정리해 보고자 한다.