Elastic Stack으로 코로나19 대시보드 만들기 - 1부 : 파이프라인 구성
얼마 전에 필자의 블로그를 보고 어느 교육 기관에서 ElasticStack에 대한 강의 요청이 들어왔다. 사실 관련 기술에 대해 지식이 아주 깊고 해박한 게 아니라서 약간의 반감부터 들었지만 ElasticStack을 전혀 모르는 사람들 기준으로 어떻게 돌아가는지에 대해서만 간단하게 소개하는 정도로 하면 된다고 하여 조심스럽지만 떨리는 마음으로 열심히 준비를 하기 시작했다. 그런데, 이런저런 이유로 갑자기 강의를 할 수 없게 되었고 그간 준비했던 내용들이 너무 아쉽지만 아무 소용이 없게 되어버렸다. 그냥 중단하기엔 아쉬운 마음이 너무 커서 준비했던 내용 중에 ‘데이터를 가지고 대시보드를 만드는 부분’은 누군가에겐 도움이 될까 싶어 블로그에 정리를 해보려 한다.
강의를 준비한 올해 1월 중순엔 Elasticsearch 버전이 7.10.2이었는데 블로그를 쓰고 있는 지금은 벌써 7.11으로 버전 업 되었다. 내가 아는 오픈소스 중에 버전업이 가장 빠른데 그렇다고 기능이 확 바뀌거나 습득하기 어렵게 바뀌진 않았다. 그만큼 사용자가 무엇을 원하는지 명확히 알고 작은 단위로 조금씩 바뀌어 가는 모습이 꽤 인상적이다.
작년 초부터 코로나19 바이러스가 전 세계적으로 퍼지기 시작했고 아직까지도 진행 중이다. 나도 전염되는 건 아닐까 하는 두려움에 어디에서 얼마나 발생했는지를 확인하기 어렵던 시절 우리나라의 뛰어난 개발자들은 누가 시키지도 않았는데 정말 감사하게도 그 현황을 한눈에 볼 수 있도록 여러 유형으로 코로나19 바이러스 대시보드를 만들기 시작한다. 그 덕분에 좀 더 현황을 보기에 편해졌고 더욱 조심하게 되는 계기가 되었다고 생각한다. 이제는 포털사이트나 각종 매체를 통해 손쉽게 코로나19 바이러스의 현황을 볼 수 있지만 이러한 데이터를 가지고 검색엔진이지만 대시보드를 구축하는데 훌륭한 기능을 가지고 있는 ElasticStack을 활용해서 ‘나만의 대시보드’를 만드는 걸 정리해보고자 한다. 본 포스팅의 일회성으로 데이터를 가지고 대시보드를 만드는 것에서 끝나는 게 아니라 지속적으로 데이터가 업데이트된다는 가정하에 전반적인 “파이프라인"을 구축한 뒤 대시보드를 만들어 두고 데이터만 갱신하면 자동으로 대시보드 또한 업데이트되는 것을 목적으로 한다.
글을 모두 작성하고 보니 양이 생각보다 길어져서 데이터를 조회하고 필터링하여 Elasticsearch에 인덱싱 하는 대시보드를 만들기 위한 일종의 “데이터 파이프라인"을 구성하는 부분과 만들어진 데이터 기반으로 Kibana의 다양한 기능을 활용하여 대시보드를 만드는 2개의 포스팅으로 나누어 정리해보겠다.
최종적으로 만들게 될 대시보드의 모습은 다음과 같다.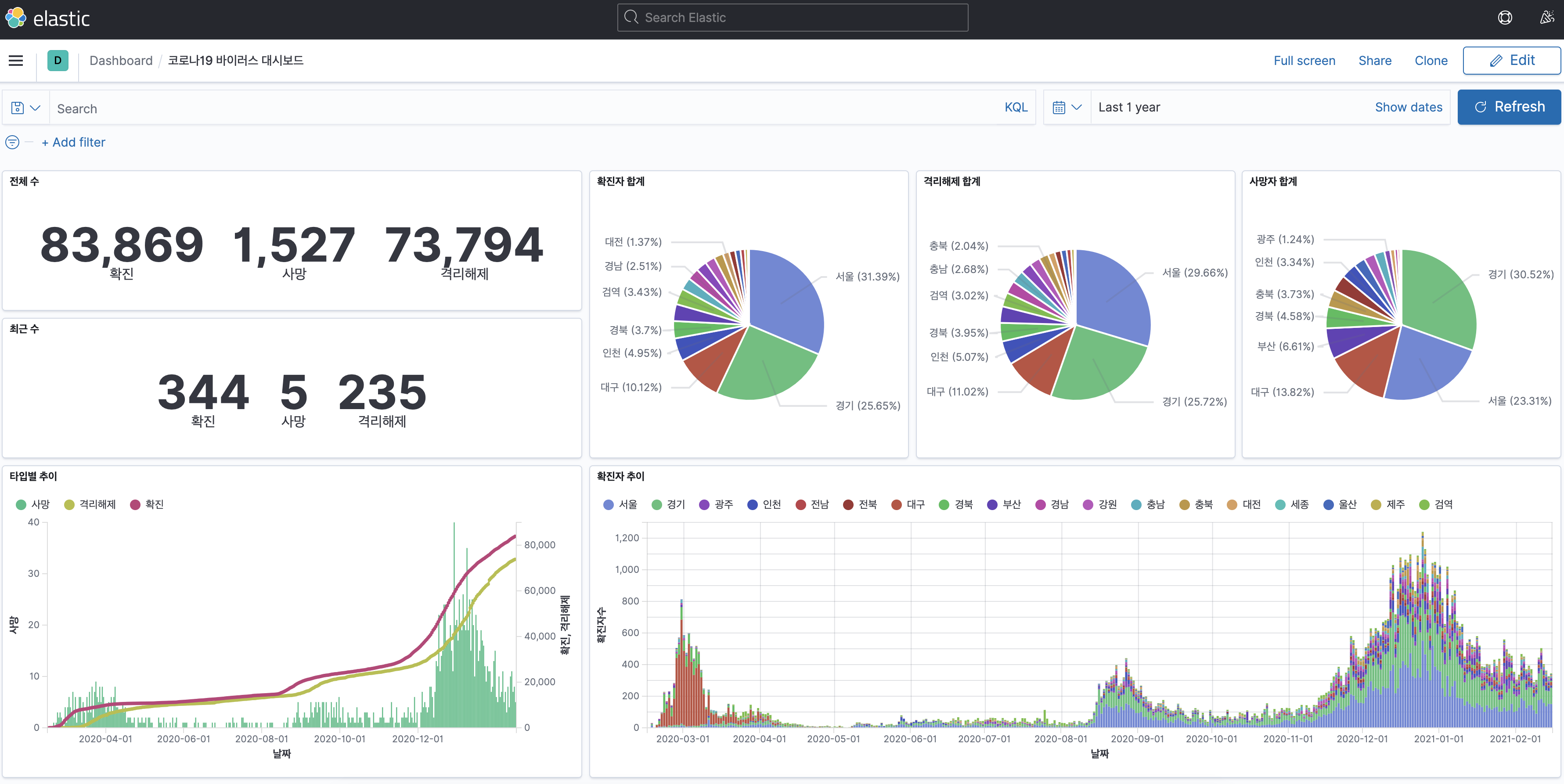
대시보드 구성 준비
예전에는 Elasticsearch, Logstash, Kibana 3가지를 가지고 ELK라 불리다 Beat라는 경량 수집기 제품이 등장하며 이 모든 걸 ElasticStack라 부르기 시작했다. (공식 홈페이지 참고) 먼저 어떤 목표와 어떤 순서로 대시보드를 구성할 것인지에 대해 정리해봐야겠다.
데이터
데이터는 공공데이터 포털에서 가져오려다 조회를 해보니 누락되는 날짜도 있었고 원하는 데이터의 품질이 생각보다 좋지 않아서 다른 곳을 찾아봐야 했다. 그러다 간결하게 정리한 데이터가 깃헙에 공개가 되어 있어서 그것을 사용하려 한다. 해당 데이터는 https://coronaboard.kr/ 에서도 사용되는 데이터라고 한다.
데이터 전처리(preprocessing)
원하는 데이터는 위 깃헙에서 제공하는 데이터 중에 지역별 발생 현황. 해당 데이터를 살펴보면 요일별로 데이터가 ‘누적’되어 저장되어 있다. 즉, 서울지역 기준으로 2020년 2월 17일에 14명이 발생했고 2020년 2월 18일에 한 명도 발생하지 않았는데 14명으로 ‘누적’되어 저장되어 있다. 사실 이대로 해도 큰 문제는 없지만 어디까지나 별도의 가공 없이 최대한 원본 데이터(raw) 가 있어야 데이터 분석 시 다양하게 활용이 가능하기에 데이터를 분석하기 전에 전처리 과정이 필요했다. 정리하면, 집계 수가 누적되지 않고 날짜 기준으로 집계된 수만 있는 데이터를 원했다.
필자는 주로 java를 가지고 개발을 하지만 가끔 간단한 스크립트성 개발은 python을 활용하는 편이기에 다소 이쁜 코드는 아니지만 데이터를 조작하려 아래와 같은 코드를 작성하였다.
import csv, requests
import pandas as pd
CSV_URL = 'https://raw.githubusercontent.com/jooeungen/coronaboard_kr/master/kr_regional_daily.csv'
# 확진, 사망, 격리해제
yesterday_data = {}
yesterday_data['서울'] = [0, 0, 0]
yesterday_data['부산'] = [0, 0, 0]
yesterday_data['대구'] = [0, 0, 0]
yesterday_data['인천'] = [0, 0, 0]
yesterday_data['광주'] = [0, 0, 0]
yesterday_data['대전'] = [0, 0, 0]
yesterday_data['울산'] = [0, 0, 0]
yesterday_data['세종'] = [0, 0, 0]
yesterday_data['경기'] = [0, 0, 0]
yesterday_data['강원'] = [0, 0, 0]
yesterday_data['충북'] = [0, 0, 0]
yesterday_data['충남'] = [0, 0, 0]
yesterday_data['전북'] = [0, 0, 0]
yesterday_data['전남'] = [0, 0, 0]
yesterday_data['경북'] = [0, 0, 0]
yesterday_data['경남'] = [0, 0, 0]
yesterday_data['제주'] = [0, 0, 0]
yesterday_data['검역'] = [0, 0, 0]
flag = False
csv_data = []
with requests.Session() as s:
download = s.get(CSV_URL)
decoded_content = download.content.decode('utf-8')
cr = csv.reader(decoded_content.splitlines(), delimiter=',')
my_list = list(cr)
for row in my_list:
if row[0] == 'date':
continue
# 다음부터 과거 데이터의 차이만 다시 저장한다.
row[2] = int(row[2]) - int(yesterday_data[row[1]][0])
row[3] = int(row[3]) - int(yesterday_data[row[1]][1])
row[4] = int(row[4]) - int(yesterday_data[row[1]][2])
# 누적 데이터 저장
yesterday_data[row[1]][0] += row[2]
yesterday_data[row[1]][1] += row[3]
yesterday_data[row[1]][2] += row[4]
csv_data.append(row)
df = pd.DataFrame(csv_data)
df.to_csv('covid19_korea.csv', index=False, header=False, encoding='utf8')
위 파이썬 스크립트를 돌려보면 아래처럼 데이터 전처리되어 csv 파일로 저장된 것을 확인할 수 있다.
- AS-IS (누적)
20200217,서울,14,0,3
20200217,부산,0,0,0
20200217,대구,0,0,0
20200217,인천,1,0,1
20200217,광주,2,0,0
...
20200217,제주,0,0,0
20200217,검역,0,0,0
20200218,서울,14,0,3
20200218,부산,0,0,0
20200218,대구,1,0,0
20200218,인천,1,0,1
20200218,광주,2,0,0
- TO-BE (당일 기준)
20200217,서울,14,0,3
20200217,부산,0,0,0
20200217,대구,0,0,0
20200217,인천,1,0,1
20200217,광주,2,0,0
...
20200217,제주,0,0,0
20200217,검역,0,0,0
20200218,서울,0,0,0
20200218,부산,0,0,0
20200218,대구,1,0,0
20200218,인천,0,0,0
20200218,광주,0,0,0
ElasticStack
간단하게 Elasticsearch와 Kibana를 설치하고 위에서 얻은 데이터를 Kibana의 import 기능을 활용하게 되면 금방 만들 수 있을 것이다. 그러나 이번 포스팅의 목표는 ElasticStack의 전반적인 흐름을 전부 경험하는 데에 있기에 데이터를 file로 수집해두면 이를 Filebeat가 읽어 Logstash로 보내고, Logstash에서는 적절하게 데이터를 필터링하여 Elasticsearch에 인덱싱하면, 연결된 Kibana에서 여러 비쥬얼라이즈를 조합하여 대시보드를 만드는 순서로 진행해보고자 한다.
ElasticStack 설치, 설정, 실행
Filebeat로 위에서 만든 csv 파일을 읽어 Logstash로 보내고, Logstash에서 필터링 후 Elasticsearch로 인덱싱을 하면, Kibana에서 연결된 Elasticsearch의 데이터를 읽어서 대시보드를 만들 것이다. 우선 설치부터 하고 각 설정들은 순서대로 살펴 가며 세팅해 보자. 설명을 하기 전에, 간단하게 Elasticsearch는 데이터 저장소, Logstash는 파이프라인(읽고 → 필터링해서 → 보낸다), Filebeat는 file의 내용 변화를 체크해서 변경 분을 수집, Kibana는 데이터를 시각화하는 툴이라 생각하면 된다.
필자는 Mac OS 기준으로 세팅하지만 ElasticStack은 다양한 운영체제를 지원하기 때문에 다른 환경에서도 충분히 따라 할 수 있을 것이다.
Elasticsearch, Kibana


공식 홈페이지에 나와있는 것처럼 다운로드하고, 압축 풀고, 실행하면 된다. (너무 간단해서 설명하기도 민망…) 과거에는 java가 설치돼야만 했었지만 최신 버전(현재 7.11)에서는 java가 내장되어 있기 때문에 별도의 설치가 필요 없다. Elasticsearch와 Kibana의 내부 설정은 추가로 건드릴 필요가 없다. Elasticsearch는 기본으로 localhost:9200으로 띄워질 것이고 Kibana는 기본으로 세팅된 localhost:9200을 Elasticsearch의 주소로 인식하기 때문에 이번 포스팅 기준으로는 그대로 다운로드해 압축 풀고 실행만 해도 무방하다. 주요 핵심은 Filebeat 와 Logstash에 있다.
# Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.0-darwin-x86_64.tar.gz
tar zxvf elasticsearch-7.11.0-darwin-x86_64.tar.gz
cd elasticsearch-7.11.0/bin
./elasticsearch
# Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.11.0-darwin-x86_64.tar.gz
tar zxvf kibana-7.11.0-darwin-x86_64.tar.gz
cd kibana-7.11.0-darwin-x86_64/bin
./kibana
Logstash

우선 설치부터 하자. 동일하게 다운 → 압축만 풀면 끝.
# Logstash
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.11.0-darwin-x86_64.tar.gz
tar zxvf logstash-7.11.0-darwin-x86_64.tar.gz
위 csv를 Filebeat가 읽어서 보내줄 것이다. 그러면 데이터를 받아서 Elasticsearch에 인덱싱하기 적절하게 필터링을 거쳐야 하는데 아래의 설정 파일(config/covid-19.conf)을 활용하여 데이터를 필터링해보자.
input {
beats {
port => 5044 # beat에서 데이터를 받을 port지정
}
}
filter {
mutate {
# 실제 데이터는 "message" 필드로 오기 때문에 csv형태의 내용을 분할하여 새로운 이름으로 필드를 추가해준다.
split => [ "message", "," ]
add_field => {
"date" => "%{[message][0]}"
"regieon" => "%{[message][1]}"
"confirmed" => "%{[message][2]}"
"death" => "%{[message][3]}"
"released" => "%{[message][4]}"
}
# 기본으로 전송되는 데이터 분석에 불필요한 필드는 제거한다. "message" 필드도 위에서 재 가공 했으니 제거한다.
remove_field => ["ecs", "host", "@version", "agent", "log", "tags", "input", "message"]
}
# "date" 필드를 이용하여 Elasticsearch에서 인식할 수 있는 date 타입의 형태로 필드를 추가해준다.
date {
match => [ "date", "yyyyMMdd"]
timezone => "Asia/Seoul"
locale => "ko"
target => "convert_date"
}
# Kibana에서 데이터 분석시 필요하기 때문에 숫자 타입으로 변경해준다.
mutate {
convert => {
"confirmed" => "integer"
"death" => "integer"
"released" => "integer"
}
remove_field => [ "@timestamp" ]
}
}
output {
# 콘솔창에 어떤 데이터들로 필터링 되었는지 확인한다.
stdout {
codec => rubydebug
}
# 위에서 설치한 Elasticsearch 로 "covid-19" 라는 이름으로 인덱싱 한다.
elasticsearch {
hosts => ["http://localhost:9200"]
index => "covid-19"
}
}
위와 같이 설정하고 Filebeat를 설치 & 실행 하기 전에 미리 실행해 둔다.
bin/logstash -f config/covid-19.conf
Filebeat

마지막으로 위에서 만든 csv 파일을 Filebeat로 캐치해서 Logstash에게 보내면 된다. 우선 아래처럼 다운을 받고 압축을 풀어두자.
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.11.0-darwin-x86_64.tar.gz
tar zxvf filebeat-7.11.0-darwin-x86_64.tar.gz
그다음 기본 설정에서 아래처럼 읽어들일 파일의 경로를 지정해 주고, Elasticsearch로의 output 은 바로 하지 않으니 주석 처리, 마지막으로 Logstash로 보내야 하기에 설정을 해준다.
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Users/taetaetae/develop/elastic-stack/covid19_korea.csv
# output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["localhost:9200"]
output.logstash:
# The Logstash hosts
hosts: ["localhost:5044"]
이제 Filebeat를 실행시키면 Filebeat에서 csv 파일을 읽고 → Logstash에서 데이터를 필터링한 다음 Elasticsearch로 보내면 → Elasticsearch에 인덱싱이 되고 → 연동된 Kibana에서 데이터가 들어온 것을 확인 가능하다.
sudo ./filebeat -e -c filebeat.yml
결과
Kibana에서 보면 아래 화면과 같이 데이터가 잘 들어온 것을 확인할 수 있다.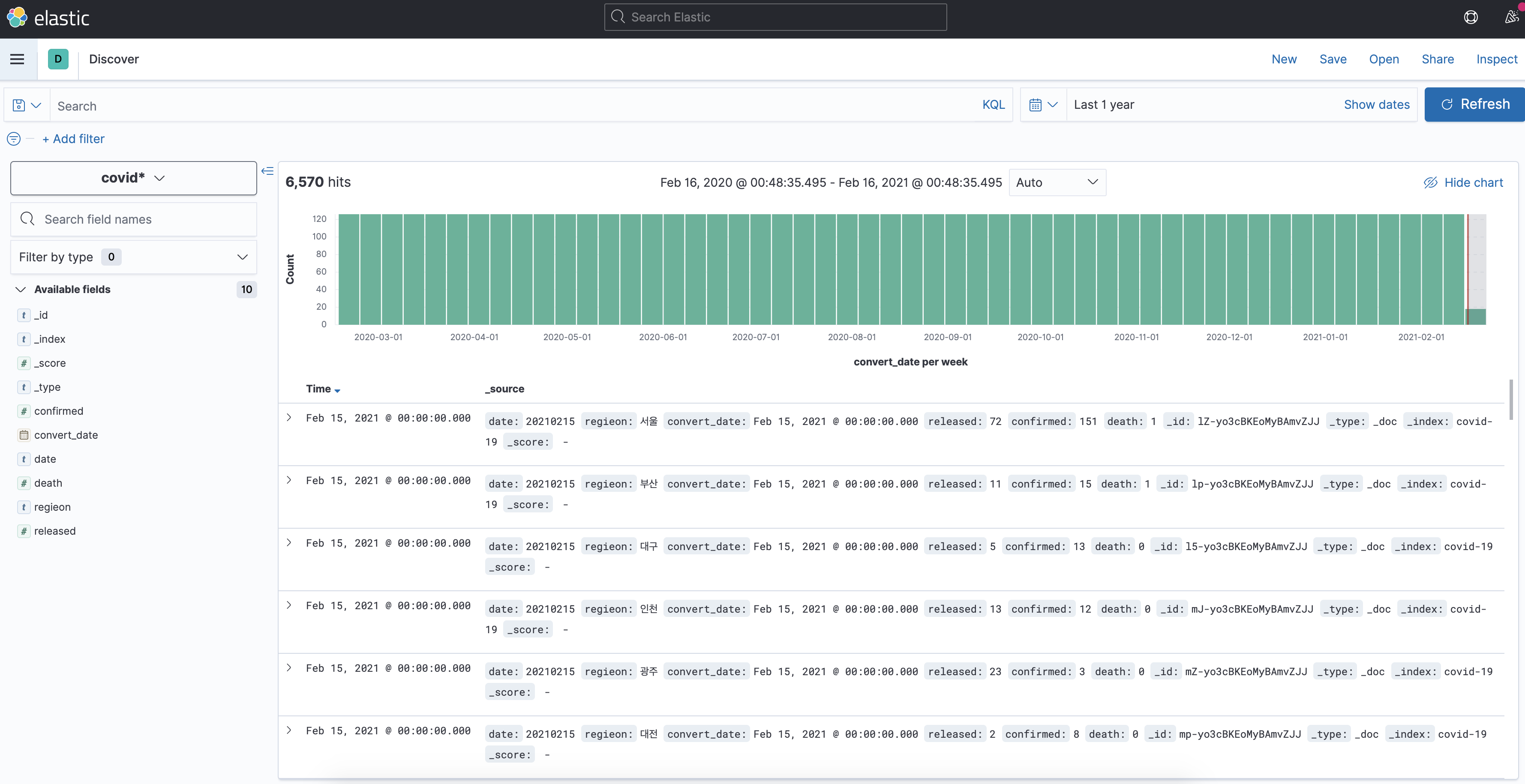
csv는 하루에 한 번 업데이트가 되니 Filebeat - Lostash - Elasticsearch가 실행 중이라 가정할 때 위에서 작성한 파이썬 스크립트를 실행하게 되면 csv 기준 한 줄이 추가된다. 그러면 추가된 하루의 데이터를 구성한 파이프라인을 통해 Elasticsearch에 자동으로 인덱싱 된다. 즉, 위에서 목표로 했던 것처럼 일회성의 대시보드가 아닌 데이터의 수급을 계속 받아 코로나19 바이러스가 종식될 때까지 사용할 수 있는 파이프라인이 구성된 것이다. 다음 편에서는 이렇게 구성한 데이터를 가지고 Kibana의 다양한 기능을 통해 대시보드를 만들어 볼 계획이다. (하루빨리 코로나19 바이러스가 세상에서 사라지기를 바라며…)