Jenkins Job을 병렬로 실행해서 속도를 개선해보자. (by. Pipeline)

관리하는 URL이 200응답을 주고 있는지 모니터링을 한다고 가정해보자. 다양한 방법이 생각나겠지만 가장 처음으로 떠오른 건 단연 Jenkins. 간단하게 사용할 언어에 맞춰 Execute Script를 작성하고 스케줄링을 걸어 놓으면 큰 수고 없이 모니터링을 구성할 수 있게 된다. 아래는 python script로 작성해 보았다.
import requests
url="http://모니터링url"
status_code = requests.get(url).status_code
if status_code != 200:
print(f'응답 실패 :{url}, status : {status_code}')
exit(1)
하지만 모니터링을 해야 하는 URL이 1개에서 여러 개로 늘어난다면 어떻게 될까? 단순하게 작성한 Script를 아래처럼 약간 수정하면 되긴 하지만 URL마다 응답속도가 다를 경우 순차적으로 실행하다 보니 실행 속도는 느릴 수밖에 없다.
import requests
urls = [
"http://모니터링url-1",
"http://모니터링url-2",
"http://모니터링url-3"
]
for url in urls:
status_code = requests.get(url).status_code
if status_code != 200:
print(f'응답 실패 :{url}, status : {status_code}')
exit(1)
이러한 경우, 빠른 속도를 보장하기 위해서는 병렬로 실행을 해야 한다는 건 누구나 다 알지만 그렇다고 Thread를 사용하기엔 벌써부터 덜컥 부담이 된다. 그렇다고 Job을 URL 개수만큼 늘리기에는 배보다 배꼽이 더 커버리고… 그러다 발견한 기능이 바로 Jenkins Pipeline!
이번 포스팅에서는 Jenkins Job을 동시에 여러 번 사용해야 하는 경우를 Pipeline을 통해서 개선한 내용에 대하여 공유해보려 한다. Jenkins Pipeline에 대해 들어만 봤는데 이번에 실제로 사용해보니 생각보다 쉽게 개선할 수 있었고 옵션들을 상황에 맞게 조합을 잘 한다면 상당히 활용성이 높아 보이는 기능인 것 같다.
기존상황
테스트를 위해 임의로 느린 응답을 생성하도록 URL을 구성하고 위에서 이야기했던 것처럼 Job 하나에 아주 심플하게 Python script를 작성하고 실행해보도록 하자. 임의로 느린 응답은 http://slowwly.robertomurray.co.uk/ 에서 제공하는 기능을 활용하였다.
import requests
urls = [
"http://slowwly.robertomurray.co.uk/delay/0/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/100/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/200/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/500/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/1000/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/2000/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/5000/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/10000/url/https://www.naver.com/",
"http://slowwly.robertomurray.co.uk/delay/20000/url/https://www.naver.com/"
]
for url in urls:
status_code = requests.get(url).status_code
if status_code != 200:
print(f'응답 실패 :{url}, status : {status_code}')
exit(1)
print(f'응답성공 : {url}')
그래서 실행해보면 50초가 소요되었다. 자, 이제 개선을 해보자!
개선을 해보자
전체적인 개선의 흐름은 하나의 Job에 모니터링하고자 하는 url을 파라미터로 받아서 처리할 수 있도록 설정하고, 이를 Jenkins Pipeline 을 통해 여러 URL을 동시에 모니터링하게 구성하는 것이다. 그러면 두 개의 Job(파라미터로 받아 모니터링하는 Job, Jenkins Pipeline Job) 만으로 보다 빠르고 효율적인 구성을 할 수 있을 것으로 상상을 하고.
Job을 범용적으로 (Jenkins paramters 활용)
위에서 샘플로 작성하였던 Python script는 url 이 늘어날수록 Job 안에 script를 수정해야 한다. 그렇게 해도 무방하지만 이번 개선의 목표는 하나의 Job을 Pipeline 이 병렬로 컨트롤하도록 설정해야 했기 때문에 Jenkins Job에 파라미터를 받을 수 있도록 아래처럼 Jenkins Job 설정에 파라미터를 설정하고 Python script 또한 수정해 주자.
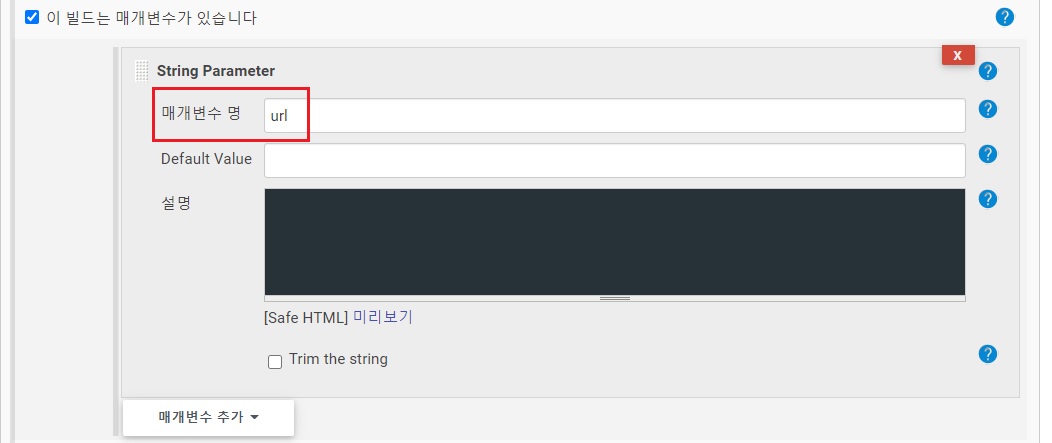
이 빌드는 매개변수가 있습니다import requests, os
url = os.environ['url']
status_code = requests.get(url).status_code
if status_code != 200:
print(f'응답 실패 :{url}, status : {status_code}')
exit(1)
print(f'응답성공 : {url}')
병렬 실행을 위한 Jenkins 설정
Jenkins Job 을 생성하면 기본적으로 Job마다의 대기열(Queue)이 있어 Job이 실행 중이라면 시작된 시간 순서대로 기다렸다가 앞선 Job이 종료가 되면 이어서 실행되는 구조이다. 하지만 우리는 Job을 병렬로 실행해야 했기에 Job 설정 중 필요한 경우 concurrent 빌드 실행 옵션을 켜줘서 기다리지 않고 병렬로 실행될 수 있도록 해준다.

필요한 경우 concurrent 빌드 실행또한 Jenkins Job 자체는 병렬로 실행되도록 설정되었다 해도 기본적으로 Jenkins 자체의 대기열은 한정되어 있기 때문에 적당히 늘려줘서 여러 개의 Job이 대기 열 없이 동시에 실행될 수 있도록 해준다.

of executorsJenkins Pipeline
Job 을 Pipeline으로 만들고 Pipeline scirpt를 작성하는데 눈여겨봐야 할 옵션들을 짚고 넘어가고자 한다.
- 우선 Pipeline에 의해 Job을 병렬로 실행을 해야 하기 때문에 아래와 같은 형식으로 작성을 해주자. 참고 : 공식문서
stages {
stage('전체 pipeline 의 이름') {
parallel {
stage('한 step의 이름') {
steps{
build job : 'heath-check'
}
}
}
}
}
- 그다음 앞서만든 Jenkins Job에 파라미터를 받을 수 있도록 해두었기에 파라미터 설정을 해주자. 참고 : 공식문서
steps{
build job : 'heath-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/0/url/https://www.naver.com/')
]
}
- 마지막으로 하나라도 실패가 나면 모든 병렬 실행 중인 Job을 중단하고 해당 Pipeline의 결과를 ‘실패’로 해야 하기 때문에
parallelsAlwaysFailFast옵션을 추가해 주자. 참고 : 공식문서 > parallelsAlwaysFailFast
options {
parallelsAlwaysFailFast()
}
위의 설정을 종합해보면 아래와 같은 groovy script 가 작성이 된다.
pipeline {
agent any
options {
parallelsAlwaysFailFast()
}
stages {
stage('health-check') {
parallel {
stage('url-1') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/0/url/https://www.naver.com/')
]
}
}
stage('url-2') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/100/url/https://www.naver.com/')
]
}
}
stage('url-3') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/200/url/https://www.naver.com/')
]
}
}
stage('url-4') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/500/url/https://www.naver.com/')
]
}
}
stage('url-5') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/1000/url/https://www.naver.com/')
]
}
}
stage('url-6') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/2000/url/https://www.naver.com/')
]
}
}
stage('url-7') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/5000/url/https://www.naver.com/')
]
}
}
stage('url-8') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/10000/url/https://www.naver.com/')
]
}
}
stage('url-9') {
steps{
build job : 'health-check',
parameters: [
string(name: 'url', value: 'http://slowwly.robertomurray.co.uk/delay/20000/url/https://www.naver.com/')
]
}
}
}
}
}
}
개선 결과
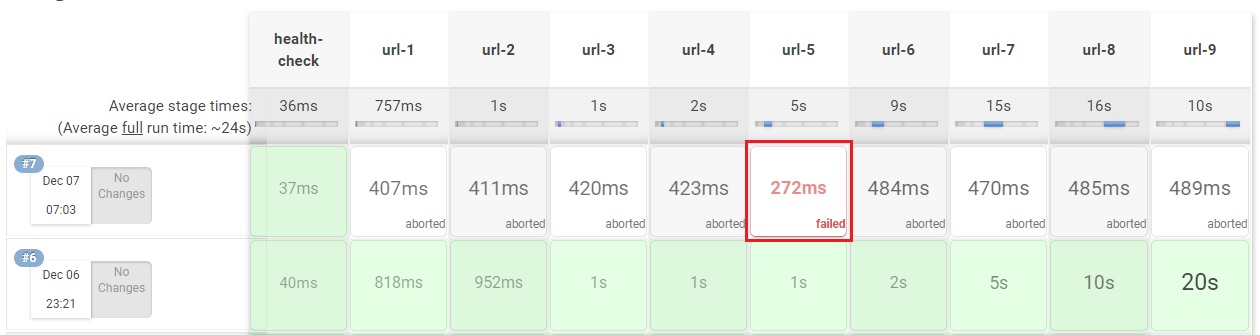
예시로 들었던 상황에서 얼마나 개선이 되었을까? 기존에 하나의 Job에서 순차적으로 진행하게 했을 경우 44초가 걸렸는데, Jenkins Pipeline 을 사용하여 Job을 병렬로 실행하게 하였더니 21초가 걸렸다. 즉, 44초에서 21초. 약 53%의 개선을 할 수 있게 되었다. 또한 아래 그림처럼 도중에 실패가 발생했을 경우 Pipeline 자체가 실패를 하게 되고 실행 중이던 다른 Job들도 중단이 되기 때문에 병렬 프로세스의 컨트롤 또한 간단하면서도 강력하게 할 수 있게 되었다.
마치며
사실 이 글을 작성하면서도 단순하게 Thread로 돌려버리면 되지 않을까라는 의문이 들었지만 보다 효율적인 기능이 있다면 실제로 테스트를 해보고 비교를 하며 검토를 해보는 것도 좋은 방법이 될 것 같았고, 나아가 늘 하던 방법만 고수하지 않고 새로운 것에 눈을 돌려보는 자세도 필요하다고 생각을 해본다. 위에서 들었던 예시는 아주 극단적인 예시지만 이러한 Jenkins Pipiline이라는 방법을 알고 있다면 이 또한 나만의 무기가 되어 다른 상황에서도 다양하게 활용해볼 수 있지 않을까 하는 기대를 해본다. (무려, groovy script 또한 이번에 처음 써보는… )