그런 개발자로 괜찮은가 - '로그 & 모니터링' 편
캐릭터를 육성하며 게임하는 경우를 생각해 보자. 더 좋은 아이템을 얻거나 퀘스트를 달성하기 위해 당신은 다양한 방법을 통해 캐릭터를 성장시킨다. 사냥을 하다 체력이 떨어지게 되면 물약을 먹고, 캐릭터의 능력 중 부족한 부분이 있으면 훈련을 더 하거나 그에 맞는 아이템을 장착하게 된다. 이렇게 캐릭터의 ‘상태’를 적절한 UI를 통해 사용자에게 알려주기 때문에 ‘확인’이 가능하고 ‘대응’이 가능하게 된다.
우리가 만드는 애플리케이션 또한 위에서 이야기 한 게임상의 캐릭터가 아닐까 싶다. 복잡한 스펙을 다양한 테스트 케이스를 만들며 로직 동작에는 이상이 없음을 확인했다면 그걸로 만족할 수 있을까? 개발자의 ‘레벨’은 이 부분에서 차이가 난다고 생각한다. 운영환경에 출시한 애플리케이션에 에러가 나는지, 트래픽이 얼마나 들어오고 있고 트래픽의 유형은 또 어떠한지, 요청에 대한 응답속도는 어떻고 서버의 시스템 지표에는 문제가 없는지 등등. 애플리케이션의 유형에 따라 다양하겠지만 적절한 로그를 이용하여 애플리케이션의 ‘상태’를 확인하고 문제가 있다면 ‘대응’하는 게 꼭 필요하다고 생각한다.
이번 포스팅에서는 크게 로깅과 모니터링에 대해 알아보고자 한다. 이를 통해 애플리케이션의 ‘개발’에만 집중하고 있던 관점을 보다 더 높은 곳에서 바라보며 애플리케이션의 ‘운영’ 측면에서도 고민해 보는 기회가 되었으면 한다.
필자는 서버 개발자이다 보니 글의 내용이 다소 서버 개발자의 시선에서 작성하게 되었다. 하지만 ‘개발자’라면 유형만 다르지 대부분 비슷하기 때문에 크게 다르지 않다고 생각한다.
로그는 어떤걸, 어떻게 남겨야 할까?
로그가 왜 필요한지에 대한 내용은 다루지 않겠다. (굳이 말하지 않아도 그만큼 중요하다는 표현이 더 어울릴 수도 있겠다.) 그렇다면 우선 어떤 로그를 남겨야 할까?
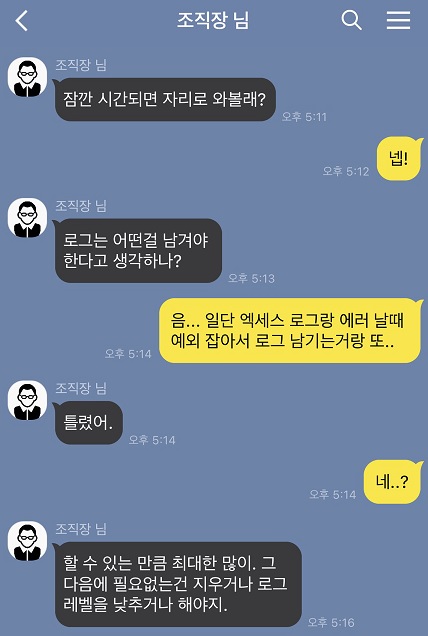
아직까지도 기억에 남아있는 예전 조직 장님과의 대화. 일단 로그는 최대한 많이 (과하게) 남겨야 한다고 생각한다. 그다음 불필요한 로그들은 제거하거나 레벨을 낮추는 등 상황에 맞도록 커스터마이징이 필요하다. 경험을 해보면 알겠지만 운영환경에 애플리케이션을 배포하고 서비스를 운영하다 보면 개발 환경에서 만나기 어렵거나 경험해보지 못한 상황이 발생하곤 한다. 이럴 때 상황에 맞는 로그들이 있다면 미리 남겨둔 로그를 통해 더 효과적으로 상황을 파악할 수 있다. 트래픽의 정보(request url, parameter, UA, remote ip 등)를 남겨서 외부에서 호출하는 형태를 분석하는데 활용할 수도 있고, 애플리케이션에서 외부로 호출을 하고 난 뒤에 받는 응답에 대해서 로그를 남겨두면 외부 통신의 오류를 파악하는 데 도움이 될 수 있다. 어떤 로그를 남겨야 하는가에 대한 고민은 운영하는 애플리케이션이 어떤 행동을 하는가에 관점을 두고 고민해보면 좀 더 쉽게 찾을 수 있을 것이라 생각한다.
로그를 남기는 방법 또한 다양하다. 시스템 로컬에 파일로 남기거나 특정 로그 서버를 설정하여 여러 대의 서버 로그를 한곳에서 볼 수도 있다. 다만 로그를 ‘남기는’ 것 또한 하나의 비용에 포함되기 때문에 애플리케이션의 기능에 최대한 영향이 가지 않도록 최대한 빠른 시간 내에 처리가 되도록 해야 한다. (혹은 비동기로 남기거나 등)
로그를 남기는 이유 중 가장 큰 이유는 ‘나중에 보기 위해서’이다. 그만큼 한번 로그를 남길 때에도 보기 좋게 남겨야 한다. 예컨대, 아래에 적어놓은 로그 방식의 경우 작은 차이지만 나중에 볼 때 꽤 큰 차이를 유발한다.
- 안좋은 예
try {
...
} catch (Exception e){
log.Error(e); // 어떤 상황이지..?
}
- 보다 조금 더 좋은 예
try {
...
} catch (Exception e){
log.Error("url : " + url + ", parameter : " + parameter + ", remote ip : " + remoteIp, e); // 로그는 가급적 자세하게 !
}
로그가 가져다 주는 또 다른 세상
로그는 또 다른 데이터가 될 수 있다. 글 목록을 보여주는 웹페이지가 있다고 가정해보자. 이때 사용자들이 어떤 글을 더 많이 읽는지 ‘클릭 지표’에 대한 로그를 남겨 둔다면 ‘인기글’ 같은 또 다른 웹 페이지가 나올 수 있을 것 같다. 만약 그 페이지가 회원만 읽을 수 있는 페이지라면 ‘20대 남성이 월요일 오후에 많이 읽는 글’ 같이 회원의 정보를 조합하여 새로운 데이터를 만들 수 있게 된다. 이러한 데이터들은 보다 더 좋은 서비스를 할 수 있게 도와줄 수 있는 밑거름이 되고 그 바탕은 로그라는 걸 명심하자.
시스템의 다양한 메트릭(Metric) 을 수집하고 이를 대시보드화하여 시스템 상태를 파악하는 데 도 도움을 줄 수 있다. 엄청난 트래픽이 예상되는 이벤트를 진행한다고 가정해보자. 이럴 때 실시간으로 로그를 수집해서 미리 구성해둔 모니터링 시스템이 없다면 무엇을 봐야 할지도 모르고 문제가 어디서 발생하는지조차 모르기 때문에 ‘서버 다운’이라는 최악의 상황까지 발생할 수 있다. 애플리케이션을 만들면 언제라도 상태를 한눈에 파악할 수 있는 모니터링 대시보드로써 문제가 발생했을 때 문제점을 빨리 파악하고 대응을 할 수 있는 최소한의 장치를 마련해 두는 연습을 해두자.
환상의 조합, 모니터링과 ‘알림’
로그를 기가 막히게 남겨두고, 모니터링 대시보드도 누가 봐도 한눈에 서비스의 상태를 볼 수 있게 정말 우아하게 만들어 두었다고 가정해보자. 그렇다면 이러한 로그와 모니터링 대시보드를 눈으로 보고 있어야 할까? 퇴근은 언제 하며 잠도 안 자고 봐야 한단 말인가? 다행스럽게도 일반적인 로그에서는 로그 레벨이라는 게 존재한다. ERROR, WARN부터 INFO, DEBUG 등 이름에서도 유추할 수 있듯이 각 레벨이 의미하는 상황에 따라 레벨을 지정하여 운영할 수 있다. 예컨대 운영환경에서는 ERROR만 남긴다거나, 개발 환경에서는 DEBUG 레벨까지 남기는 설정을 할 수 있다.

출처 : https://gifer.com/en/SzNQ
로그 시스템에서는 알림 기능을 제공하고 있다. (제공하지 않는 경우 직접 구현을 해야 할 수도 있다.) 그래서 지정한 주기 내에서 지정한 횟수로 로그가 발생하면 이를 감지하여 시스템 관리자에게 메신저나 문자 등으로 알림을 발송해 주는 시스템이 필요하다. 단, 이러한 알림이 너무 잦거나 알림 발송의 기준이 너무 추상적이라면 ‘알림’에 대한 인식이 둔해질 수 있기 때문에 정말 필요한 알림만 발송될 수 있게 해둬야 한다. 반대로, 알림을 받고는 있지만 지금 당장 대응하지 않을 이슈라면 알림을 받지 않는 게 정상이다. 그렇기에 앞서 이야기 한 로그 레벨 설정이 정말 중요하다. (이 로그가 정말 ERROR 레벨인가? WARN이나 INFO는 아닐까?)
마치며
개발을 할 때 변수의 자료형이 몇 바이트이고 이를 얼마나 사용하기 때문에 메모리를 얼마나 사용하고 cpu는 몇 core이니까 얼마나 자원을 사용하고 가비지 컬렉션이 차지하는 용량은 … 이렇게 개발 단계부터 디테일하게 개발하진 않는다. (물론 엄청난 성능을 요하는 core 모듈 개발이라면 모를까…) 보통은 기능 개발을 끝내고선 로그와 시스템 지표를 확인하고 그다음에 튜닝을 하는 방식으로 하게 된다. 요즘엔 애플리케이션의 기반이 되는 서버(혹은 클라이언트)의 성능이 좋기 때문에 더욱더 개발을 끝난 뒤에 성능 테스트의 결과에 따라 서버를 증설할지 로직을 튜닝할지 결정하게 되는데 여기에서도 가장 핵심은 ‘로그’ 와 ‘모니터링’이다.
문제가 발생하면 가장 먼저 해야 할 게 무엇일까? 선임/동료 개발자에게 물어보기일까? 아님 restart(재부팅)? 입이 닳도록 아깝지 않을 정도로 ‘로그’를 먼저 봐야 한다고 말하고 싶다. 만약 재부팅을 하더라도 문제 되고 있는 현재 시스템 상태의 로그를 남겨두고 (java에서는 heap/thread dump 등) 재부팅을 한다거나 하는 습관. 개발을 아무리 잘해도, 테스트 코드 작성을 아무리 잘해도 ‘로그’와 ‘모니터링’을 빼놓고선 서비스 운영을 논할 수 없기에 꼭 다양한 연습으로 습관화하는 게 필요할 것 같다.