네트워크 모니터링이 궁금할땐 ? Packetbeat !

모니터링은 서비스 로직 개발 만큼 한번씩 고민해보고 경험해 봤을 중요한 영역이라 할 수 있다. 그중 웹서버에서 제공해주는 엑세스 로그는 운영하고 있는 웹서비스에 대해 여러가지 측면에서 분석할 수 있는 가장 강력한 아이템 중에 하나라고 생각한다. 이를 통해 사용자들이 어떤 url을 많이 호출하고, 어떤 user-agent형태를 사용하는지 알게 되면 그에 따라 서비스 전략을 변경할수도 있고 악의적으로 공격적인 요청에 대해 웹서버단에서 차단을 할 수 있기 때문이다.
이렇게 inbound 트래픽(외부에서 들어오는 요청)에 대해서는 엑세스 로그를 잘 분석하면 기존의 웹 어플리케이션과는 전혀 무관하게 모니터링이 가능하지만 반대로 outbund 트래픽(외부로 나가는 요청)에 대해서는 어떤식으로 모니터링을 할 수 있을까?

이미지 출처 : https://www.app24moa.com/feedDetail/2/2002
예컨데, 날씨 서비스를 하기 위해 외부에서 서울날씨라는 페이지를 조회했을 경우 기상청 API에서 넘겨받은 데이터를 가공하여 보여준다고 가정해보자. 이때 기상청에서 제공해주는 특정 API중에 어느 하나가 늦게 응답이 온다거나, 특정시간대에 에러응답을 받을경우 과연 이를 어떤식으로 모니터링 할수 있을까? 어플리케이션 코드에 모니터링을 위한 코드를 추가할 것인가? 혹 하나의 서버에서 A모듈은 java로, B모듈은 python으로 개발되었을 경우 각각 모듈마다 모니터링을 위한 코드를 추가하는 식으로 하다보면 비지니스 로직을 방해하거나 오히려 추가한 코드 또한 관리해야 하는 배보다 배꼽이 더 커져버릴 상황도 생길수 있다.
어플리케이션의 비지니스 로직과는 무관하게 서버 자체에서 외부로 나가는 네트워크 트래픽에 대해 모니터링을 할 수 있는 가벼우면서도 심플한 모듈을 찾고 싶었다. 어플리케이션의 개발언어가 무엇이든 상관없이 별도의 에이전트 형식으로 띄워두기만 하면 네트워크 트래픽을 수집 및 분석, 나아가서는 모니터링까지 할수있는… 그래서 찾다보니 역시나 이러한 고민을 누군가는 하고 있었고 오픈소스까지 되어있는 Elastic Stack 의 Beat중 Packetbeat라는 데이터 수집모듈을 알게 되었다.
역시 내가 하고있는 고민은 이미 누군가 했던 고민들… 이러한 고민에 대해 해결하는 방법을 보다 빨리 찾는게 경쟁력이 될텐데…
이번 포스팅에서는 Packetbeat 에 대해 간단히 알아보고 이를 활용하여 outbound 트래픽에 대해 모니터링을 해보며 어떤식으로 활용할 수 있는지에 대해 알아보고자 한다.
Packetbeat ?
ElasticStack 중에 데이터 수집기 플랫폼인 Beats중 네트워크 트래픽 데이터에 대해 수집을 할 수 있는 데이터 수집기를 제공하고 있다. pcap라이브러리를 이용하여 서버의 네트워크 레벨에서 데이터를 수집 및 분석한 후 외부로(Elasticsearch, Logstash, Kafka 등) 전송해주는 경량 네트워크 패킷 분석기라고 공식 홈페이지에 소개되고 있다.
몇번 사용해보면서 느낀 장점들은 다음과 같다.
- 설치 및 실행이 너무 간단하다.
- 설정값 튜닝을 통해 간단하지만, 그러한 간단함에 비해서 너무 강력한 수집이 가능하다.
- 앞서 이야기 했던 어플리케이션 코드와는 전혀 무관하게 작동한다.
무엇을 해볼것인가?! (a.k.a. 목표)
필자가 운영하는 Daily-DevBlog 라는 서비스가 있다. (갑분 서비스 홍보) 여러 사람들의 rss를 조회하고 파싱해서 메일을 보내주는 서비스 인데, packetbeat 사용 예시를 들기위해 조금 변형하여 모든 rss를 접근하고 가장 최신글의 제목을 출력하는 아주 간단한 python 스크립트로 outbound 트래픽을 발생시켜 보고자 한다.
그리고 packetbeat 를 이용하여 외부로 호출되는 트래픽을 수집하고 Elasticsearch 로 인덱싱 하여 최종적으로는 어느 rss의 속도가 가장 느린지 실행되는 python코드와는 전혀 관련없이 모니터링 해보고자 한다.
python 코드는 다음과 같다.
참고로 필자는
awesome-devblog의 운영자분께 해당 데이터 사용에 대해 허락을 받은 상태이다.
import requests, yaml, feedparser
blog_info_list_yml_url = 'https://raw.githubusercontent.com/sarojaba/awesome-devblog/master/db.yml'
blog_info_list_yml = requests.get(url=blog_info_list_yml_url).text
blog_info_yaml_parse_list = yaml.load(blog_info_list_yml)
for blog_info in blog_info_yaml_parse_list :
if 'rss' not in blog_info.keys() or not blog_info['rss']:
continue
rss_url = blog_info['rss']
try :
parse_feed = feedparser.parse(rss_url)
except :
continue
parse_feed_data = parse_feed.entries[0]
print(blog_info['name'], '|', parse_feed_data['title'], '|', parse_feed_data['link'])
위 코드를 실행하면 아래처럼 아주 간단하게 블로그 주인의 이름과 최신글 제목, 링크가 출력이 된다.

백문이 불여일견? 백견이 불여일타!
언제 어디서부터 유래된 이야기 인지는 모르지만 “백번 듣는것이 한번 보는것보다 못하고, 백번 보는것이 한번 타자 치는것보다 못하다” 라는 개발버전 속담이 있다. 자, 위에서 정의한 목표를 이루기 위해 실제로 각종 모듈을 설치해 보도록 하자! ( 필자가 테스트 했던 서버의 환경은 CentOS 7.4 64Bit 이니 참고 )
- Elasticsearch 이왕 설치하는거 가장 최신버전인 7.3.1을 설치해보자! (버전업이 빨라도 너~무 빨라…)
// 다운을 받고
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.1-linux-x86_64.tar.gz
// 압축을 푼다음
tar -zxvf elasticsearch-7.3.1-linux-x86_64.tar.gz
cd elasticsearch-7.3.1/conf
// 각종 설정후
vi elasticsearch.yml
node.name: node-1
network.host: 0.0.0.0
discovery.seed_hosts: ["localhost"]
cluster.initial_master_nodes: ["node-1"]
// 실행
bin/elasticsearch
http://server-url:9200접근시 아래처럼 나오면 설치 성공
{
"name": "node-1",
"cluster_name": "elasticsearch",
"cluster_uuid": "---",
"version": {
"number": "7.3.1",
~~~
},
"tagline": "You Know, for Search"
}
- Kibana
// 다운을 받고
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.3.1-linux-x86_64.tar.gz
// 압축을 푼 다음
tar -zxvf kibana-7.3.1-linux-x86_64.tar.gz
cd kibana-7.3.1-linux-x86_64/config
// 각종 설정후
vi kibana.yml
server.host: "~.~.~.~"
elasticsearch.hosts: ["http://~.~.~.~:9200"]
// 실행
bin/kibana
http://server-url:5601접근시 키바나 화면이 나오면 설치 성공
- Packetbeat
// 다운을 받고
wget https://artifacts.elastic.co/downloads/beats/packetbeat/packetbeat-7.3.1-linux-x86_64.tar.gz
// 압축을 푼 다음
tar -zxvf packetbeat-7.3.1-linux-x86_64.tar.gz
// 각종 설정후 실행 (root 권한으로 실행해야 함)
sudo chown root:root packetbeat.yml
sudo vi packetbeat.yml
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["~.~.~.~:9200"]
sudo ./packetbeat -e -c packetbeat.yml
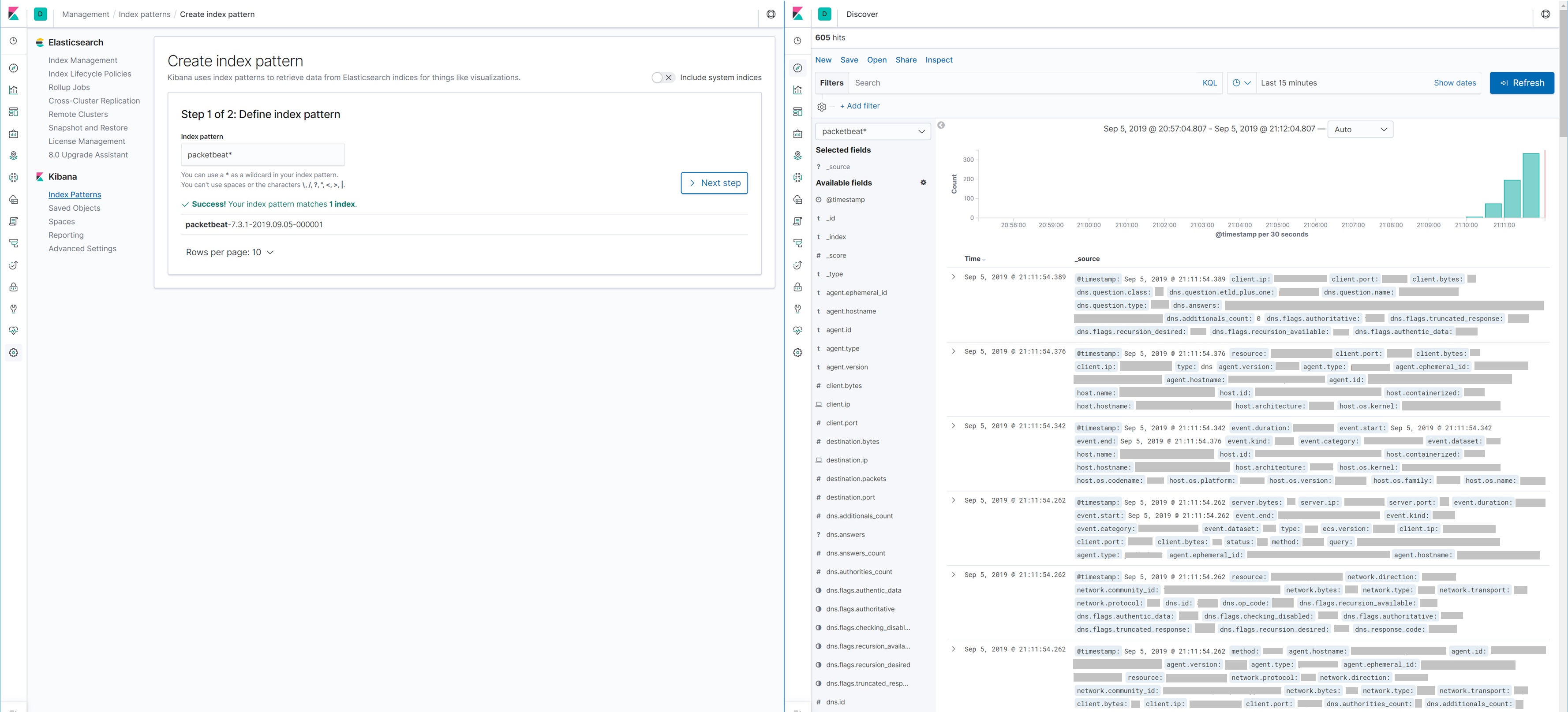
이렇게 하고나서 키바나에 가보면 아래처럼 Packetbeat 인덱스 패턴을 만들수 있고 수집이 되고있는것 까지 확인 가능하다.
무엇을 모니터링 할 수 있을까?
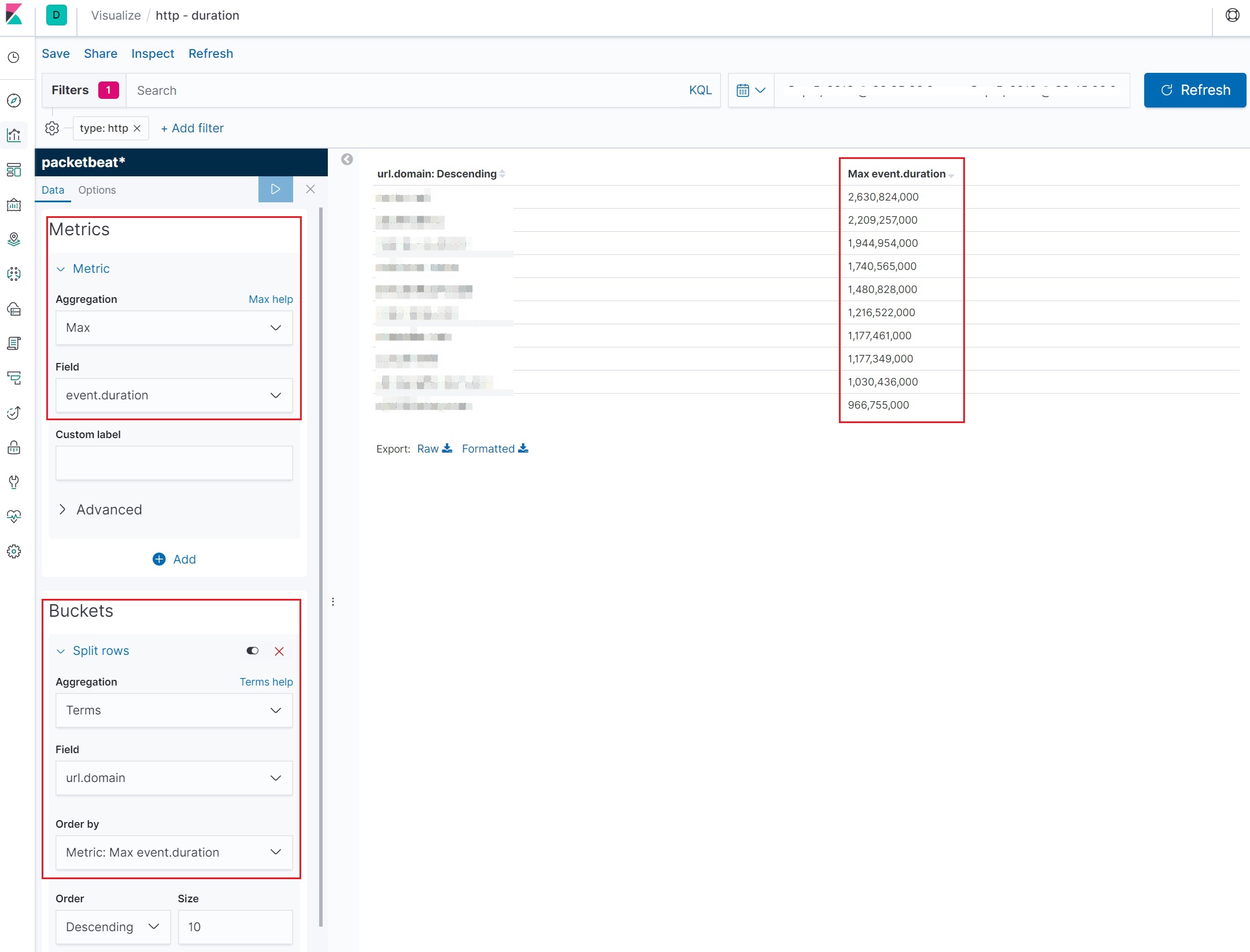
이제 각종 구성은 했으니 처음에 목표한 어느 rss가 가장 느린가를 체크해 볼 시간이다. python 스크립트를 돌리면 packetbeat 에 의해 네트워크 트래픽이 수집~분석~Elasticsearch에 인덱싱이 되고 이를 키바나의 비쥬얼라이즈를 통해 적절하게 만들어보면 아래처럼 너무나도 간단하게 어느 rss의 응답속도가 가장 느린지 확인할 수 있다. event.duration 필드는 기본적으로 nano second 이다보니 아래 그림에서는 2.6초가 가장 오래걸린 rss url 이라 볼 수 있다.
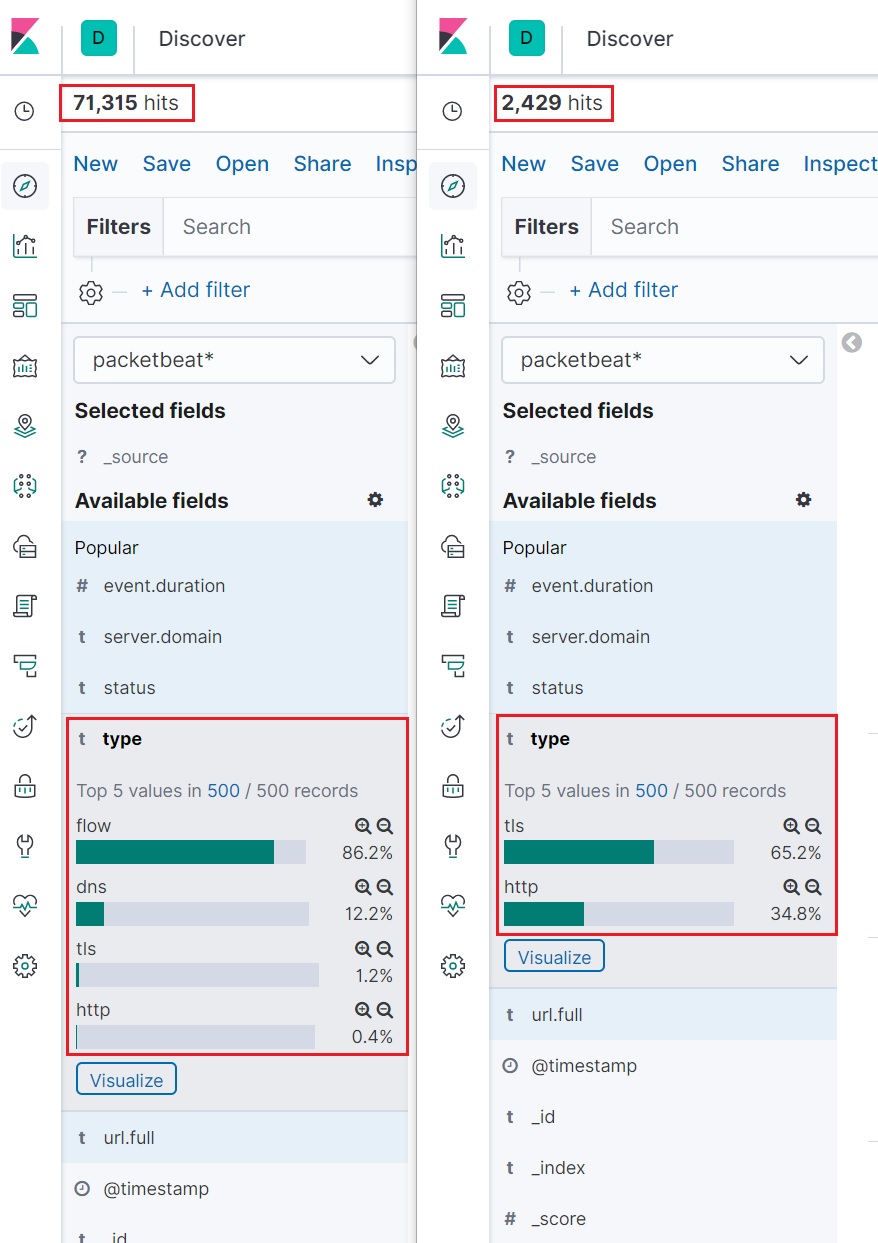
한가지 더, packetbeat를 설치하고 기본 설정으로 실행하게 되면 불필요한(outbound 트래픽만을 수집하겠다던 목표와는 무관한) 데이터들도 수집되다보니 아무래도 cpu에 불필요한 부하가 발생할수 있고(아무래도 모든 네트워크 트래픽을 트래킹 하고 분석해야하니…) Elasticsearch 에도 불필요한 데이터가 인덱싱 되곤 한다. 그래서 지금의 Packetbeat 뿐만 아니라 오픈소스를 사용할 경우엔 설정값들을 정확히 알고 목적에 맞는 커스터마이징은 필수인듯 하다. 필자는 http의 outbound 트래픽만을 보고 싶었기 때문에 아래처럼 packetbeat 설정을 하고 다시 실행 해보면 Elasticsearch 에 수집되는 도큐먼트 사이즈가 확연하게 차이나는 것을 확인할 수 있다.
packetbeat.protocols: # 아래 2개 이외에는 전부 주석처리
- type: http
ports: [80] # 80 port 의 http를 수집하겠다.
- type: tls
ports:
- 443 # 443 의 tls를 수집하겠다.
processors:
- drop_event.when.equals.network.direction : "inbound" # inbound는 수집하지 않겠다.
사실 위 설정값은 페이스북 한국 Elasticsearch 유저그룹에 문의해서 알게된 내용이다. 역시 커뮤니티 파워, 집단지성의 힘을 다시한번 느낄 수 있었다. (모르면 물어보자! + 문제에 대해 좀더 잘 검색하도록 노력하자!)
마치며
Packetbeat 을 사용하면서 가장 좋았던 점은 기존 로직과는 전혀 무관하게 작동하는 점이 가장 좋았다. 이러한 점은 어느 상황에서도 서비스 코드 디펜던시가 없어 자유롭게 활용이 가능하다는 뜻으로 해석을 해보곤 한다.

이미지 출처 : https://namu.wiki/w/%EB%82%98%EB%8A%94%20%EC%9E%90%EC%97%B0%EC%9D%B8%EC%9D%B4%EB%8B%A4
필자는 최근 운영환경에도 packetbeat를 적용해서 outbound 트래픽을 모니터링 하고 문제가 있는 엔드포인트에 대해 자동으로 점검을 하는 시스템을 만들려고 하고 있는데, 네트워크 패킷을 전부 까보며(?) 아무래도 cpu 성능에 지장을 줄수밖에 없는 오픈소스 모듈이다보니 다양한 테스트를 통해 서비스 운영에 영향이 없도록 설정값들을 튜닝해 가며 적용해봐야 할 것 같다. (무작정 좋다고 적용하다 오히려 큰 화를 부를 수 있다…)
내가 맛있어 하는 음식이 남들도 맛있으리란 법 없듯, 소개팅에 나가기전 준비한 멘트가 전부 먹히리라는 법 없듯… 모든 상황에는 튜닝은 필수다. 그 튜닝을 얼마나 잘, 그리고 센스있게 하냐가 포인트!