누구나 할 수 있는 엑세스 로그 분석 따라 해보기 (by Elastic Stack)

필자가 Elastic Stack을 알게된건 2017년 어느 여름 동기형이 공부하고 있는것을 보고 호기심에 따라하며 시작하게 되었다. 그때까지만 해도 버전이 2.x 였는데 지금 글을 쓰고있는 2019년 2월초 최신버전이 6.6이니 정말 빠르게 변화하는것 같다. 빠르게 변화하는 버전만큼 사람들의 관심도 (드라마틱하게는 아니지만) 꾸준히 늘어나 개인적으로, 그리고 실무에서도 활용하는 범위가 많아지고 있는것 같다.
그래서 그런지 최근들어 (아주 코딱지만큼 조금이라도 더 해본) 필자에게 Elastic Stack 사용방법에 대해 물어보는 주변 지인들이 늘어나고 있다. 그리고 예전에 한창 공부했을때의 버전보다 많이 바꼈기에 이 기회에 “그대로 따라만 하면 Elastic Stack을 구성할 수 있을만한 글"을 써보고자 한다. 사실 필자가 예전에 “도큐먼트를 보기엔 너무 어려워 보이는 느낌적인 느낌” 때문에 삽질하며 구성한 힘들었던 기억을 되살려 최대한 심플하고 처음 해보는 사람도 따라하기만 하면 “아~ 이게 Elastic Stack 이구나!”, “이런식으로 돌아가는 거구나!” 하는 도움을 주고 싶다.
+ 그러면서 최신버전도 살펴보고… 1석2조, 이런게 바로 블로그를 하는 이유이지 않을까? 다시한번 말하지만 도큐먼트가 최고 지침서이긴 하다…
Elastic 공식 홈페이지에 가면 각 제품군들에 대해 그림으로 된 자세한 설명과 도큐먼트가 있지만 이들을 어떤식으로 조합하여 사용하는지에 대한 전체적인 흐름을 볼 수 있는 곳은 없어 보인다. (지금 보면 도큐먼트가 그 어디보다 설명이 잘되어 있다고 생각되지만 사전 지식이 전혀없는 상태에서는 봐도봐도 어려워 보였다.) 이번 포스팅에서는 Apache access log를 Elasticsearch에 인덱싱 하는 방법에 대해 설명해보고자 한다.
전체적인 흐름
필자는 글보다는 그림을 좋아하는 편이라 전체적인 흐름을 그림으로 먼저 보자.
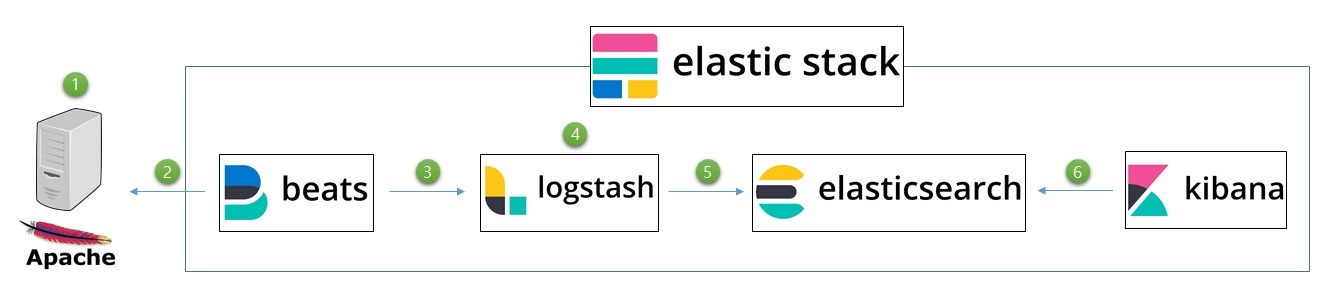
- 외부에서의 접근이 발생하면 apache 웹서버에서 설정한 경로에 access log가 파일로 생성이 되거나 있는 파일에 추가가 된다. 해당 파일에는 한줄당 하나의 엑세스 정보가 남게 된다.
- fileBeat에서 해당 파일을 트래킹 하고 있다가 라인이 추가되면 이 정보를 logstash 에게 전달해준다.
- logastsh 는 filebeat에서 전달한 정보를 특정 port로 input 받는다.
- 받은 정보를 filter 과정을 통해 각 정보를 분할 및 정제한다. (ip, uri, time 등)
- 정리된 정보를 elasticsearch 에 ouput 으로 보낸다. (정확히 말하면 인덱싱을 한다.)
- elasticsearch 에 인덱싱 된 정보를 키바나를 통해 손쉽게 분석을 한다.
한번의 설치고 일련의 과정이 뚝딱 된다면 너무 편하겠지만, 각각의 레이어가 나뉘어져있는 이유는 하는 역활이 전문적으로(?) 나뉘어져 있고 각 레이어에서는 세부 설정을 통해 보다 효율적으로 데이터를 관리할 수 있기 때문이다.
beats라는 레이어가 나오기 전에는 logstash에서 직접 file을 바라보곤 했었는데 beats가 logstash 보다 가벼운 shipper 목적으로 나온 agent 이다보니 통상 logstash 앞단에 filebeat를 위치시키곤 한다고 한다.
전체적인 그림은 위와 같고, 이제 이 글을 보고있는 여러분들이 따라할 차례이다. 각 레이어별로 하나씩 설치를 해보며 구성을 해보자. 설치순서는 데이터 흐름의 순서에 맞춰 다음과 같은 순서로 설치를 해야 효율적으로 볼수가 있다. (아래순서대로 하지 않을경우 설치/시작/종료 를 각각의 타이밍에 맞추어 해줘야 할것 같아 복잡할것같다.)
elasticsearch → logstash → kibana → filebeat
이 포스팅은 CentOS 7.4에서 Java 1.8, apache 2.2가 설치되어있다는 가정하에 보면 될듯하다. 또한 각 레이어별 설명은 구글링을 하거나 Elastic 공식 홈페이지에 가보면 자세히 나와있으니 기본 설명은 안하는것으로 하고, 각 레이어의 세부 설정은 하지 않는것으로 한다.
Elasticsearch
다운받고 압축풀고 심볼릭 경로 만들고 (심볼릭 경로는 선택사항)
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz
$ tar zxvf elasticsearch-6.6.0.tar.gz
$ ln -s elasticsearch-6.6.0 elasticsearch
설정 파일을 열고 추가해준다.
$ cd elasticsearch/conf
$ vi elasticsearch.yml
path.data: /~~~/data/elasticsearch (기본경로에서 변경할때추가)
path.logs: /~~~/logs/elasticsearch
network.host: 0.0.0.0 # 외부에서 접근이 가능하도록 (실제 ip를 적어줘도 됨)
elasticsearch 의 시작과 종료를 조금이나마 편하게 하기위해 스크립트를 작성해줌 (이것또한 선택사항)
$ cd ../bin
$ echo './elasticsearch -d -p es.pid' > start.sh
$ echo 'kill `cat es.pid`' > stop.sh
$ chmod 755 start.sh stop.sh
혹시 아래와 같은 에러가 발생할경우 공식문서 대로 진행해준다.
ERROR: [1] bootstrap checks failed
[1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
> sudo /sbin/sysctl -w vm.max_map_count=262144
이렇게 하고 시작을 한뒤 브라우저에서 http://{ip}:9200 로 접속하면 다음과 같이 설치된 elasticsearch에 기본 정보가 나오게 되고 이렇게 elasticsearch의 설치 및 실행이 완료되었다.
{
"name": "@@@",
"cluster_name": "elasticsearch",
"cluster_uuid": "@@@",
"version": {
"number": "6.6.0",
"build_flavor": "default",
"build_type": "tar",
"build_hash": "@@@",
"build_date": "2019-01-24T11:27:09.439740Z",
"build_snapshot": false,
"lucene_version": "7.6.0",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
Logstash
다운을 받고 압축풀고 심볼릭 링크 설정
$ wget https://artifacts.elastic.co/downloads/logstash/logstash-6.6.0.tar.gz
$ tar -zxvf logstash-6.6.0.tar.gz
$ ln -s logstash-6.6.0 logstash
logstash가 실행될때 설정값 파일을 만들어준다.
$ cd logstash/config
$ vi access_log.conf
# beats 에서 5044 port 로 데이터를 input 받겠다는 의미
input {
beats {
port => "5044"
}
}
# grok 필터를 활용하여 엑세스로그 한줄을 아래처럼 파싱하겠다는 의미
# 해당 필터는 apache의 로깅 설정에 의해 만들어지는 파일의 포멧에 맞추어 설정해야한다.
filter {
grok {
match => { "message" => ["%{IPORHOST:clientip} (?:-|%{USER:ident}) (?:-|%{USER:auth}) \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:httpMethod} %{NOTSPACE:uri}(?: HTTP/%{NUMBER:httpversion})?|-)\" %{NUMBER:responseCode} (?:-|%{NUMBER:bytes}) (?:-|%{NUMBER:bytes2})( \"%{DATA:referrer}\")?( \"%{DATA:user-agent}\")?"] }
remove_field => ["timestamp","@version","path","tags","httpversion","bytes2"]
}
}
# 정제된 데이터를 elasticsearch 에 인덱싱 하겟다는 의미
# index 이름에 날짜 형태로 적어주면 인덱싱 하는 시점의 시간에 따라 인덱싱 이름이 자동으로 변경이 된다. (아래는 월별로 인덱스를 만들경우)
output {
elasticsearch {
hosts => [ "{elasticsearch ip}:9200" ]
index => "index-%{+YYYY.MM}"
}
}
실행은 다음과 같이 &연산자를 활용하여 background로 실행하게 한다.
$ bin/logstash -f config/access_log.conf &
이렇게 해서 실행을 하고 에러없이 정상적으로 실행이 된뒤 프로세스가 올라와 있으면 (ps -ef | grep logstash) 성공된 상태라 볼수있다.
Kibana
역시 다운받고 압축풀고 심볼릭 링크 설정
$ https://artifacts.elastic.co/downloads/kibana/kibana-6.6.0-linux-x86_64.tar.gz
$ tar -zxvf kibana-6.6.0-linux-x86_64.tar.gz
$ ln -s kibana-6.6.0-linux-x86_64 kibana
외부에서 접근을 하기위해 ip를 적어주고, 연결할 elasticsearch 주소또한 적어준다.
$ cd kibana/config
$ vi kibana.yml
server.host: "@.@.@.@"
elasticsearch.hosts: ["http://@.@.@.@:9200"]
실행은 bin 폴더로 이동후에 다음과 같이 실행시켜준다. 별다른 에러가 없으면 외부에서 접근이 가능한지 확인해보자.
$ cd bin/
$ nohup ./kibana &
접속 : http://@.@.@.@/5601
Filebeat
다운 → 압축해제 → 심볼릭링크
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-linux-x86_64.tar.gz
$ tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz
$ ln -s filebeat-6.6.0-linux-x86_64 filebeat
filebeat가 실행될때의 설정파일을 작성해준다.
$ cd filebeat
$ vi access_log.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /~~~/logs/apache/access.log.* # 실제 엑세스 파일의 경로
tail_files: true # filebeat 시작시점 기준 파일 끝에서부터 로깅을 읽기 시작
ignore_older: 1m # filebeat 시작시점 기준 1분전의 내용은 무시
close_inactive: 2m
clean_inactive: 15m
logging.level: info
logging.to_files: true
logging.files: # filebeat가 실행되면서 남기는 로깅파일 정보. 도큐먼트를 읽어보는것을 추천한다.
path: /~~~/logs/filebeat
name: test-filebeat-log
keepfiles: 7
rotateeverybytes: 524288000
output.logstash: # 최종적으로 output 할 logstash의 정보를 입력해준다.
hosts: ["@.@.@.@:5044"]
위와 같이 설정파일을 작성한 다음 아래처럼 실행을 하면 엑세스 파일의 내용이 filebeat를 거치고 logstash를 거쳐 최종적으로 elasticsearch 에 도달하게 된다. 기존에 엑세스 로그가 양이 많다면 그 정보를 다 읽는 시간이 걸리므로 주의한다. (filebeat 자체적으로 해당 파일의 offset을 관리하기 때문)
$ ./filebeat -c access_log.yml -d publish &
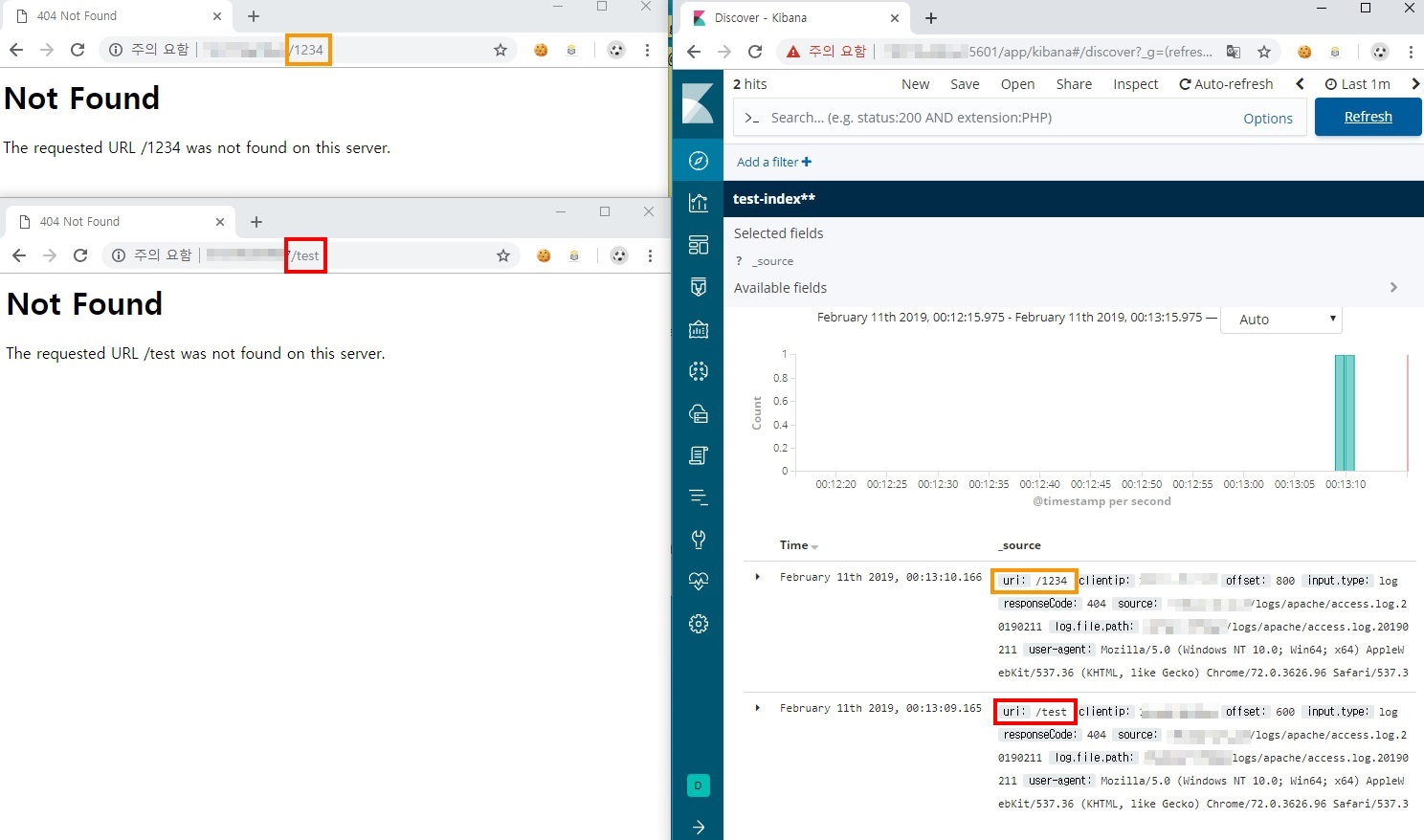
최종 확인
왼쪽에는 해당 서버를 호출하고 오른쪽에는 키바나를 띄워논뒤 테스트를 해보면 아래처럼 access log를 확인이 가능하다. (apache만 띄워놓은 상태라 404상태로 나오긴 한다..) 불필요한 필드가 있다면 logstash 의 filter에서 remove 하면되고 키바나에서 각 정보를 가지고 다양한 유의미한 데이터를 만들어볼 수 있게 되었다.
마치며
막상 해보면 (해보기전에 느끼는 두려움보다는) 엄청나게 미친듯이 어렵지는 않는데… 맨땅에 해딩이든 뭐든 시작해보고 만들어보는게 중요하다고 다시한번 생각해본다. 필자는 elasticsearch 2.4버전에 대해 영어로된 문서를 보며 설치하고 구성하며 (왜 한글로 된 문서가 한명도 없을까…) 하는 아쉬움에 있었는데 이 글이 필자처럼 설치하는데 비슷한(?) 고충을 느낀 사람들에게 도움이 되었으면 한다. 마지막으로 세부 설정값들로 인해 성능이나 기능이 다양하게 바뀔수 있으니 공식 도큐먼트를 보는것을 강력 추천하고 싶다.