시계열 데이터를 분석하여 미래 예측 하기(Anomaly Detection)

급변하는 날씨를 예측하려면 어떠한 정보가 있어야 할까? 또는 마트를 운영하는 담당자인 경우 매장 운영시간을 정해야 한다면 어떠한 기준으로? 뜨거운 감자인 비트코인 시장에서 수익을 얻으려면 어떤 정보들이 있어야 물리지(?) 않을수 있을까?
위 질문에 공통된 정답은 예전 기록들인것 같다. 날씨예측은 기상청에서 과거 기록들을 보고 비가 올지 말지를 결정하고 ( 과거 날씨 서비스를 담당해봤지만 단순히 과거 기록들로 예측한다는건 불가능에 가깝긴 하다. ) 매장 운영시간은 예전에 손님들이 언제왔는지에 대한 데이터를 보고. 비트코인이나 주식은 차트를 보고 어느정도는 상승장일지 하락장일지 추측이 가능하다고 한다. ( 물론 호재/악재에 따라 흔들리지만..ㅠㅠ..?? )
이처럼 시간의 흐름에 따라 만들어진 데이터를 분석하는것을 시계열 데이터 분석이라 부르고 있다. 필자가 운영하는 서비스에서 시계열 데이터 분석을 통해 장애를 사전에 방지하는 사례를 공유 해보고자 한다.
상황파악부터
손자병법에는 지피지기 백전불태 라는 말이 있다. 그만큼 현 상황을 잘 알아야 대응을 잘할수 있다는것. 필자가 운영하는 서비스는 PG(Payment Gateway) 서비스로 쇼핑몰같은 온/오프라인 사업자와 실제 카드사와의 중간 역활을 해주고 있다. 이를테면 사용자가 생수를 10,000원에 XX카드로 구매해줘 라고 요청이 오면 그 정보를 다시 형식에 맞춰 카드사로 전달하여 사용자가 물건을 구매할수 있도록 해준다.

요구사항 및 과거 데이터 분석
서비스를 운영해보니 감지하기 어려운 상황들이 있었다.
- 연동하는 쇼핑몰에서 문제가 발생하거나 네트워크 문제가 발생할경우 즉, 트래픽이 평소보다 적게 들어올 경우
- 정상적인 에러(e.g. 잔액부족) 가 갑자기 많이 발생할 경우
이를 분석하기위해 기존의 트래픽/데이터를 분석해봐야 했다.

위 그래프는 결제데이터 카운트 인데 어느정도 패턴을 찾을수 있다.

위 그래프는 에러카운트 인데 일정한 패턴 속에서 어느 지점에서는 튀는것을 확인할수 있다. (빨간색 영역) 그렇다면 어떤 방법으로 장애상황보다 앞서서 감지를 할수 있을까? ( 장애 : 어떠한 내/외부 요인으로 인해 정상적인 서비스가 되지 않는 상태 )
장애발생 전에 먼저 찾아보자!
가장 간단하게는 기존 데이터를 보고 수동으로 설정하는 방법이 있을수 있다. 예로들어 자정 즈음에는 결제량이 가장 많기때문에 약 xx건으로 설정해두고, 새벽에는 결제량이 가장 적기 때문에 약 yy건으로 설정해둔 후 에러 건수나 결제건수에 대해 실시간으로 검사를 해가면서 설정한 값보다 벗어날 경우 알림을 주는 방법이다. 하지만 아무리 과거 데이터를 완벽하게 분석했다 할지라도 24시간 모든 시점에서 예측은 벗어날 수밖에 없다. (예로들어 쇼핑 이벤트를 갑작스럽게 하게되면 결제량은 예측하지 못할정도로 늘어날테고…) 또한 설정한 예측값을 벗어날 경우 수동으로 다시 예측값을 조정해줘야 하는데, 이럴꺼면 24시간 종합 상황실에서 사람이 직접 눈으로 보는것 보다 못할것 같다. (인력 리소스가 충분하다면 뭐… 그렇게 해도 된다.)
지난 데이터와 비교하기
일주일 기준으로 지난 일주일과의 데이터를 비교해보는 방법또한 있다. 간단하게 설명하면 이번주 월요일 10시의 데이터와 지난주 월요일 10시의 데이터의 차이를 비교해보는 방법이다. 키바나에서 클릭 몇번만으로 시각화를 도와주는 Visualize 기능을 통해 지난 일주일과 이번주를 비교해보면 아래 그래프처럼 표현이 가능하다.

이 경우도 지난주 상황과 이번주 상황이 다른 경우에는 원하는 비교 항목 외에 다른 요인이 추가되기 때문에 원하는 비교를 할수가 없고 위에서 수동으로 설정하는 방법과 별반 다를바 없을것으로 생각된다.
조금더 우아하게! (언제부턴가 우아하단 말을 좋아하는것 같다..)
개발자는 문제에 대해서 언제나 분석을 토대로 접근을 하는것을 목표로 해야한다. 언제부턴가 Hot한 머신러닝을 도입해 보고 싶었으나 아직 그런 실력이 되질 못하고… 폭풍 구글링을 통해 알게된 Facebook에서 만든 Prophet이라는 모듈을 활용해보고자 한다.
https://opensource.fb.com/#artificial 이곳에 가보면 여러 Artificial Intelligence 관련된 오픈소스들중에 Prophet 모듈을 찾을수 있다. 다행히도 BSD License라서 실무에서도 다양하게 활용할수 있을것으로 보인다. 친절하게도 Quick Start을 통해 어떤식으로 예측을 하는지 보여준다. 참고로 Python 과 R 을 지원한다. (python 의 대단함을 다시금 느끼며…)
구성은 CentOS 7 + python3.6 + jenkins 를 활용한다. (python 경험이 부족하므로 코드가 허접할수도 있으니 양해바란다.)
데이터 분석시 가장 많이 사용된다는 Pandas와 대규모 다차원 배열을 쉽게 처리 할 수 있게 해주는 numpy, 그리고 bprophet를 비롯한 필요한 모듈들을 pip로 설치해준다.
pip install pandas
pip install fbprophet
pip install numpy
필요한 모듈들을 import를 한다.
import matplotlib
matplotlib.use('Agg') // centos 서버 환경에서 돌릴경우 예측결과를 그래프로 보는 과정에서 오류가 발생한다. 이를 방직하기 위해 해당 코드를 적어준다.
import pandas as pd
import requests, datetime
from fbprophet import Prophet
기존에 데이터들은 모두 실시간으로 elasticserach에 인덱싱 중이기 때문에 rest api 를 활용하면 쉽게 데이터를 얻을수가 있다. (RDB로 관리를 했더라면… 배보다 배꼽이 더 큰 상황이였지 않았을까 하는 생각이 든다.)
# 현재 시 기준 2주 (24 x 14 시간) 전의 데이터를 가져온다.
day_gap = 14
now_datetime = datetime.datetime.now()
end_time = datetime.datetime(now_datetime.year, now_datetime.month, now_datetime.day, now_datetime.hour, 0,0)
end_time_stamp = str(int(end_time.timestamp() * 1000))
start_time = end_time - datetime.timedelta(days=day_gap)
start_time_stamp = str(int(start_time.timestamp() * 1000))
url = 'http://elasticsearch:9200/_msearch'
headers = {
"Content-Type" : "application/x-ndjson"
}
es_data = '{"index":["index_name"]}\n{"size":0,"query":{"bool":{"must":[{"range":{"log_time":{"gte":' + start_time_stamp + ',"lte":' + end_time_stamp + '}}}]}},"aggs":{"2":{"date_histogram":{"field":"log_time","interval":"1h", "time_zone":"Asia/Tokyo"}}}}\n'
response_list = requests.post(url=url, headers=headers, data=es_data.encode('utf-8')).json()['responses'][0]['aggregations']['2']['buckets']
print('기준 : ' + str(start_time) + ' ~ ' + str(end_time))
# es 데이터 중 시간값을 형식에 바꾸면서 key-value 형태로 정제한다.
query_result = {}
for data in response_list :
query_result[data['key_as_string'].replace('T',' ').replace('.000+09:00', '')] = data['doc_count']
elasticsearch에서 aggregation을 활용하여 데이터를 1시간 단위로 가져올경우 데이터가 없는 경우를 대비해 비어있는 시간에 해당하는 카운트를 0으로 맞춰주기 위하여 loop를 돌며 데이터를 정제해준다. (이 방법보다 더 좋은 방법이 분명 있을것이다…)
anomaly_detection_base_data = {}
for data in range(24 * day_gap) :
key_date_time = start_time.strftime('%Y-%m-%d %H:00:00')
if key_date_time in query_result :
anomaly_detection_base_data[key_date_time] = query_result[key_date_time]
else :
anomaly_detection_base_data[key_date_time] = 0
start_time = start_time + datetime.timedelta(hours=1)
pandas 를 활용하여 데이터를 DataFrame 형식에 맞춰준 다음 시간기준으로 다음 24시간의 데이터를 예측하도록 한다.
df = pd.DataFrame(list(anomaly_detection_base_data.items()), columns=['ds', 'y'])
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=24 , freq='H')
forecast = m.predict(future)
실제 집계한 값과 예측값을 비교하여 알림발생 유무를 결정한다.
# 현재시간 -1시간 전 실제 집계
check_datetime = now_datetime - datetime.timedelta(hours=1)
check_datetime = check_datetime.strftime('%Y-%m-%d %H:00:00')
check_datetime_count = query_result[check_datetime]
print('실제 집계수 : ' + check_datetime + ' → ' + str(check_datetime_count))
# 예측 최대치
forecast_max_count = forecast[forecast.ds == check_datetime]['yhat_upper'].values[0]
print('예측 최대치 : ' + check_datetime + ' → ' + str(forecast_max_count))
여기서는 에러 카운트가 평소와는 다르게 발생할 경우에 알림을 발송을 하려 하기때문에 아래처럼 구성을 해준다.
if check_datetime_count > forecast_max_count :
# 예측한 결과를 이미지로 저장후 알림에 포함시켜준다.
forecast_graph = m.plot(forecast, plot_cap=False, xlabel='time', ylabel='count');
file_name = 'forecast_graph.png'
forecast_graph.savefig(file_name)
이런 python script를 jenkins 를 활용하여 1시간에 한번씩 실행될수있도록 구성해 두고 문제가 발생할때는 아래처럼 메일로 알림을 받는다.
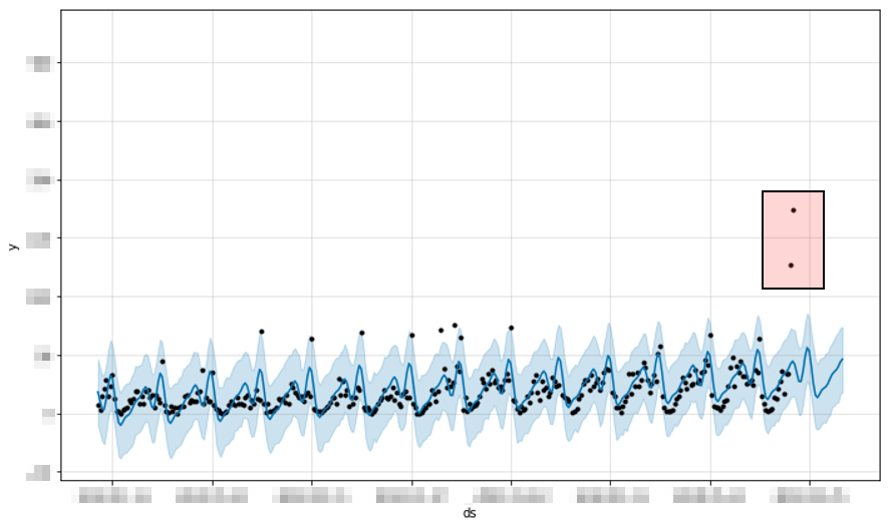
위 그래프를 분석하면 다음과 같다.
- 검정색 점 : 실제 데이터
- 파란 실선 : 트랜드 그래프
- 하늘색 음영 : 예측한 최대/최소치의 영역 빨간색으로 표시한 점 두개를 보면 예측을 벗어난것을 확인할수 있고 실제로 저 시간대에 내부적 이슈로 인해 에러가 많이 발생한 경우이다. (장애 발생 시점)
이런식으로 구성을 해두면 앞서 수동으로 최대/최소 수치를 정해두고 이탈했는지에 대해서 모니터링 하는것보다 훨씬더 우아하게 모니터링을 할수있다. 물론 해당 모듈이 완벽하다는 소리는 아니다. 필자도 해당 모듈을 사용하다보니 어떤 경우에서는 예측수치와 실제 데이터가 비슷한 경우가 있어 알람을 받은 경우도 있다. 예전 포스팅에서도 이야기 했듯 정답은 없는것 같다. 상황에 맞춰서 지속적으로 커스터마이징을 해야하는게 개발자의 숙명 아닐까 싶다.
마치며
사실 이렇게 시계열 데이터라는 단어나 Prophet같은 오픈소스를 검색할수 있었던건 작년 Elastic{ON}Tour 에서 봤던 Elastic X-pack의 머신러닝 기능 때문이다. 그때 받은 충격(?)이 아직까지 있는건지 이렇게 오픈소스로 비슷하게나마 구현할수 있었던 원동력이 된것 같다. 기회가 되면 X-pack을 구매해서 운영하는 서비스에 머신러닝을 활용해서 이러한 시계열 데이터에 대해 분석해보고싶다.