내 서버에는 누가 들어오는걸까? (실시간 user-agent 분석기)
Desktop 및 스마트폰의 대중화로 다양한 OS와 브라우저들을 사용하게 되었다. 이때, 내가 운영하는 웹서버에 들어오는 사람들은 무슨 기기로 접속을 하는 것일까? 혹여 특정 OS의 특정 브라우저에서만 안되는 버그를 잡기 위해 몇일밤을 고생하며 겨우 수정했는데… 과연 그 OS의 브라우저에서는 접속은 하기나 하는걸까? (ㅠㅠ) 만약, 접속 사용자의 Device 정보를 알고있다면 고생하며 버그를 잡기 전에 먼저 해당 Device 사용율을 체크해 볼수도 있고(수정이 아닌 간단한 얼럿으로 해결한다거나?) 비지니스 모델까지 생각해야하는 서비스라면 타겟팅을 정하는 등 다양한 활용도가 높은 것이 바로 User-Agent라고 한다(이하 UA). 일반 Apache 를 웹서버로 운영하고 있다고 가정을 하고 어떻게 분석을 할수 있었는지, 그리고 분석을 하며 좀더 우아한(?) 방법은 없는지 알아 보고자 한다.
User-Agent가 뭐야?
백문이 불여일타(?)라 했던가, 우선 http://www.useragentstring.com 를 들어가보자. 그러면 자신의 OS 및 브라우저 등 정보를 파싱해서 보여주는데 위키백과에 따르면 ‘사용자를 대신하여 일을 수행하는 소프트웨어 에이전트’라고 한다. 즉, UA만 알아도 어떤 기기/브라우저를 사용하는지 알 수 있다는것. mozilla에 가보면 스팩 등 다양한 UA를 볼수가 있는데 특히 맨 아래보면 기기/브라우저별로 지원정보가 나와있다. 여기서도 보면 모든 모바일 삼성 브라우저를 제외하고는 전부 지원이 되는걸 확인할수 있다.

기존의 방법
그럼 어떻게 내 서버에 들어온 사용자들의 UA를 확인할 수 있을까? (앞서 Apache를 웹서버로 운영한다고 했으니) Apache access log 에는 Apache에서 제공해주는 모듈을 이용해 접속한 클라이언트의 정보가 남겨지곤 한다. 그렇다면 이 access log를 리눅스 명령어든 엑셀로 뽑아서든지 활용해서 정규식으로 포맷팅 하고 그 결과를 다시 그룹화 시키면 얼추 원하는 데이터를 추출해 낼수 있다. ( 버거형들이 만들어둔 정규식을 가져다 사용할수도 있겠다. https://regexr.com/?37l4e )
하지만, 우선 자동화가 안되어있어 데이터를 구하고 싶을때마다 귀차니즘에 걸릴수 있고 슈퍼 개발자 파워를 기반으로(?) 데이터 추출을 자동화 한들 실시간으로 보고싶을땐 제한사항이 많다.
좀더 나은 방법(?)
실시간 데이터를 모니터링 하는데에는 다양한 오픈소스와 다양한 툴이 있겠지만 경험이 부족한건지 아직까진 ElasticStack 만한걸 못본것 같다. 간단하게 설명을 하면 access log 를 사용하지 않고 front단에서 javascript 로 UA를 구한다음 이러한 정보를 받을수 있는 API를 만들어 그쪽으로 보내면 서버에서 해당 UA를 분석해서 카프카로 보내고 ..!@#$%^blabla… ^^; 그림으로 보자.

front단에서는 navigator.userAgent를 활용하여 UA를 구할수 있었고, API에서는 UA를 받고 파싱을 하는데 관련 코드는 다음과 같이 작성하였다.
private static final String VERSION_SEPARATOR = ".";
private void userAgentParsingToMap(String userAgent, Map<String, Object> dataMap) {
HashMap browser = Browser.lookup(userAgent);
HashMap os = OS.lookup(userAgent);
HashMap device = Device.lookup(userAgent);
dataMap.put("browserName", browser.get("family"));
dataMap.put("browserVersion", getVersion(browser));
dataMap.put("osName", os.get("family"));
dataMap.put("osVersion", getVersion(os));
dataMap.put("deviceModel", device.get("model"));
dataMap.put("deviceBrand", device.get("brand"));
}
private String getVersion(HashMap dataMap) {
String majorVersion = (String)dataMap.get("major");
if (StringUtils.isEmpty(majorVersion)) {
return StringUtils.EMPTY;
}
String minorVersion = (String)dataMap.get("minor");
String pathVersion = (String)dataMap.get("path");
StringBuffer sb = new StringBuffer();
sb.append(majorVersion);
if (!StringUtils.isEmpty(minorVersion)) {
sb.append(VERSION_SEPARATOR);
sb.append(minorVersion);
}
if (!StringUtils.isEmpty(pathVersion)) {
sb.append(VERSION_SEPARATOR);
sb.append(pathVersion);
}
return sb.toString();
}
참고로 Java단에서 UA를 파싱하는 parser가 여러가지가 있는데 그중 uap_clj라는 모듈이 그나마 잘 파싱이 되어서 사용하게 되었다.
- 모듈별 비교
| 모듈 | Browser | OS | Device |
|---|---|---|---|
| eu.bitwalker.useragentutils.UserAgent | O | 불명확함 (Android 5.x) | X |
| net.sf.uadetector.UserAgentStringParser | O | O | 불명확함 (Smartphone) |
| uap_clj.java.api.* | O | O | O |
- Parsing 비교
- UA
"Mozilla/5.0 (Linux; Android 5.1.1; Nexus 6 Build/LYZ28E) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"
- 결과
- Browser : {patch=3239, family=Chrome Mobile, major=63, minor=0}
- OS : {patch=1, patch_minor=, family=Android, major=5, minor=1}
- Device : {model=Nexus 6, family=Nexus 6, brand=Generic_Android}
위와 같이 구성을 하면 Elasticsearch에 인덱싱된 데이터를 Kibana에서 입맛에 맞게 실시간으로 볼수있게 되었다!
하지만 API를 만드는 부분 + front에서 별도의 javascript가 들어간다는 부분 + 운영하는 모든 페이지에 해당 javascript를 넣어야지만 볼수있는 부분 등 약간 아쉬운 감이 있다. 뭔가 더 좋은 방법이 없을까? 깔끔하면서도 우아한 방법. 짱구를 열심히 더 굴려보자.
좀더 우아한 방법?
Logstash 에는 UA를 파싱해주는 filter plugin 이 있다고 한다. (링크) 이 방법과 예전에 포스팅한 access log 를 elasticsearch 에 인덱싱 하는 방법을 혼합하면 위에서 걱정했던 문제들을 아주 깔끔하게 해결할 수 있을것 같다.
지난 포스팅 : 링크
물론 글보다는 그림설명이 더 빠르니 전체적인 흐름을 그림으로 보자.

① front 단에서 javascript로 UA를 구하고 ② 별도로 만든 API에 데이터를 전송한뒤 ③ API에서는 이를 또 파싱하는 작업을 logstash 의 user-agent filter plugin으로 깔끔하게 해결할 수 있었다.
우선 apache에서 access log format 은 다음과 같고
"%h %l %u %t \"%r\" %>s %b %D \"%{Referer}i\" \"%{User-Agent}i\""
logstash쪽 설정은 다음과 같이 해주었다.
input {
file {
path => "/~~~/access.log.*"
start_position => "beginning"
codec => multiline {
pattern => "^%{IPORHOST}"
negate => true
what => previous
auto_flush_interval => 1
}
}
}
filter {
grok {
match => { "message" => ["%{IPORHOST:clientip} (?:-|%{USER:ident}) (?:-|%{USER:auth}) \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:httpMethod} %{NOTSPACE:uri}(?: HTTP/%{NUMBER:httpversion})?|-)\" %{NUMBER:responseCode} (?:-|%{NUMBER:bytes}) (?:-|%{NUMBER:bytes2})( \"%{DATA:referrer}\")?( \"%{DATA:user-agent}\")?"] }
remove_field => ["timestamp","@version","path","tags","httpversion","bytes2"]
}
useragent {
source => "user-agent"
}
if [os_major] {
mutate {
add_field => {
os_combine => "%{os} %{os_major}.%{os_minor}"
}
}
} else {
mutate {
add_field => {
os_combine => "%{os}"
}
}
}
if [os] =~ "Windows" {
mutate {
update => {
"os_name" => "Windows"
}
}
}
if [os] =~ "Mac" {
mutate {
update => {
"os_name" => "Mac"
}
}
}
}
output {
if [user-agent] != "-" and [user-agent] !~ "Java" {
kafka {
bootstrap_servers => "~~~"
topic_id => "~~~"
codec => json{}
}
}
}
설정하는데 가장 큰 어려웠던 점은 grok filter 패턴을 작성하는데 많은 시간을 할해야만 했다. 개인적으로 http://grokconstructor.appspot.com/do/match?example=2 에서 테스트 해보면서 패턴을 작성할수 있어 그나마 다행이였다.
또한 logstash에서 파싱해주는 정보를 조금 다듬기 위해 mutate filter 를 사용해서 필드를 조합/수정 하였다.
위처럼 적용을 하고 한두시간 수집을 해보니 Elasticsearch에 아래와 같은 도큐먼트가 생성이 된것을 확인할수 있었다.
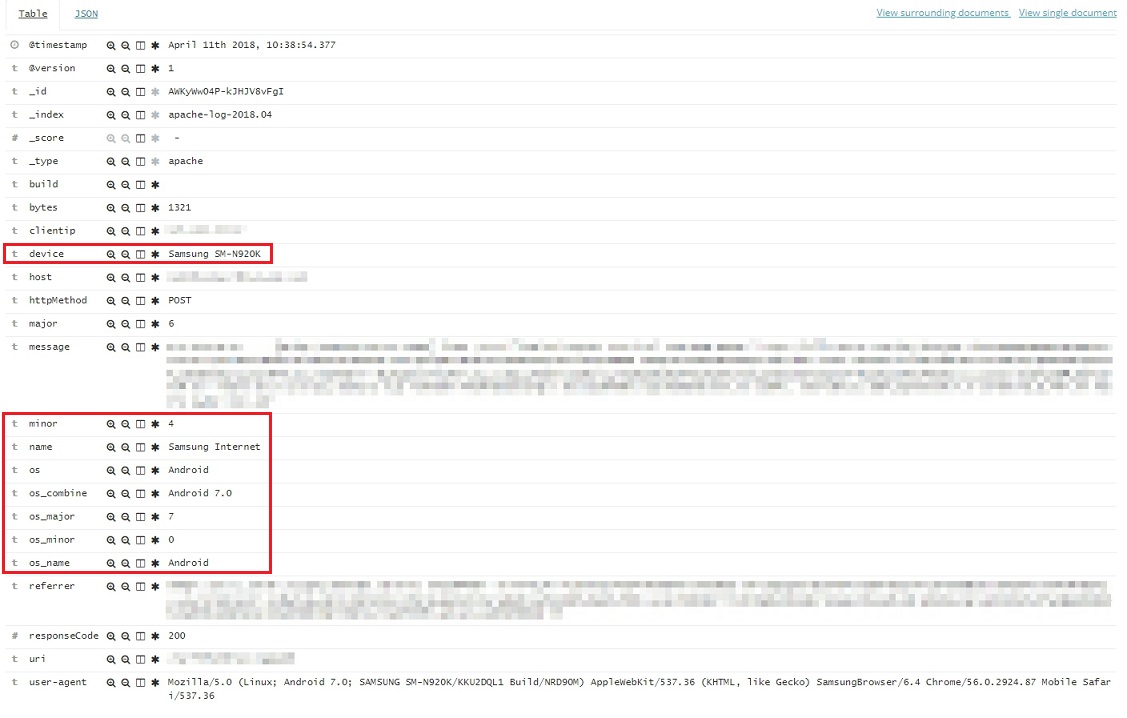
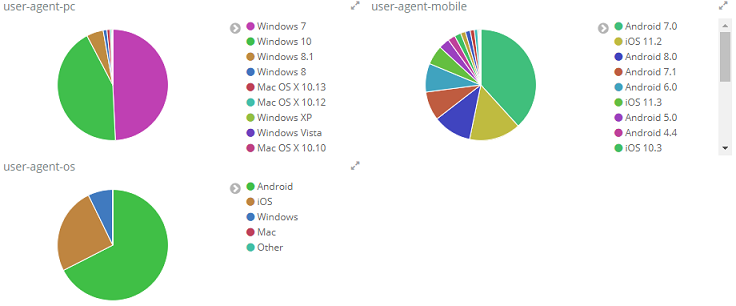
이 정보들을 잘 조합해서 Kibana에서 보면 다음과 같이 볼수 있다.
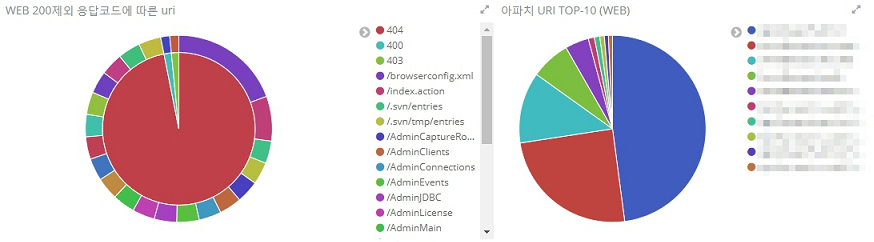
UA는 아니지만 기왕 한김에 Access log의 uri를 분석해보면 아래처럼 볼수도 있겠다.
마치며
사실 logstash filter plugin을 작성하면서 뭔가 if-else로 분기처리한게 아쉽긴 하지만 만족할만한 결과를 얻을수 있어서 다행이라고 생각하고, 역시 데이터를 raw형태로 보는것보다 시각화해서 보는게 훨씬더 이해도를 높일수 있다는걸 다시금 실감할수 있었던 좋은 시간이였다. 그런데.. 이 방법말고 더 우아한 방법은 없으려나..?;;