아파치 엑세스 로그를 엘라스틱서치에 인덱싱 해보자.
apache access log 를 분석하고 싶은 상황이 생겼다. 아니 그보다 apache access에 대해서 실시간으로 보고싶었고, log를 검색 & 데이터를 가공하여 유의미한 분석결과를 만들어 보고 싶었다. 그에 생각한것이 (역시) ElasticStack.
처음에 생각한 방안은 아래 그림처럼 단순했다.
하지만, 내 단순한(?) 예상은 역시 빗나갔고 logstash에서는 다음과 같은 에러를 내뱉었다.
retrying individual bulk actions that failed or were rejected by the previous bulk request
request가 많아짐에 따라 elasticsearch가 버벅거리더니 logstash에서 대량작업은 거부하겠다며 인덱싱을 멈췄다. 고민고민하다 elasticsearch에 인덱싱할때 부하가 많이 걸리는 상황에서 중간에 버퍼를 둔 경험이 있어서 facebook그룹에 문의를 해봤다. https://www.facebook.com/groups/elasticsearch.kr/?multi_permalinks=1566735266745641 역시 나보다 한참을 앞서가시는 분들은 이미 에러가 뭔지 알고 있으셨고, 중간에 버퍼를 두고 하니 잘된다는 의견이 있어 나도 따라해봤다. 물론 답변중에 나온 redis가 아닌 기존에도 비슷한 구조에서 사용하고 있던 kafka를 적용. 아, 그전에 현재구성은 Elasticsearch 노드가 총 3대로 클러스터 구조로 되어있는데 노드를 추가로 늘리며 스케일 아웃을 해보기전에 할수있는 마지막 방법이다 생각하고 중간에 kafka를 둬서 부하를 줄여보고 싶었다. (언제부턴가 마치 여러개의 톱니바퀴가 맞물려 돌아가는듯한 시스템 설계를 하는게 재밌었다.) 아래 그림처럼 말이다.

그랬더니 거짓말 처럼 에러하나 없이 잘 인덱싱이 될수 있었다. logstash가 양쪽에 있는게 약간 걸리긴 하지만, 처음에 생각한 구조보다는 에러가 안나니 다행이라 생각한다.
이 구조를 적용하면서 얻은 Insight가 있기에, 각 항목별로 적어 보고자 한다. ( 이것만 적어놓기엔 너무 없어보여서.. )
access log 를 어떻게 분석하여 인덱싱 할것인가?
apache 2.x를 사용하고 별도의 로그 포맷을 정하지 않으면 아래와 같은 access log가 찍힌다.
123.1.1.1 - - [25/Jan/2018:21:55:35 +0900] "GET /api/test?param=12341234 HTTP/1.1" 200 48 1144 "http://www.naver.com/" "Mozilla/5.0 (iPhone; CPU iPhone OS 11_1_2 like Mac OS X) AppleWebKit/604.3.5 (KHTML, like Gecko) Mobile/15B202 NAVER(inapp; blog; 100; 4.0.44)"
그럼 이 로그를 아무 포맷팅 없이 로깅을 하면 그냥 한줄의 텍스트가 인덱싱이 된다. 하지만 이렇게 되면 elasticsearch 데이터를 다시 재가공하거나 별도의 작업이 필요할수도 있으니 중간에 있는 logstash에게 일을 시켜 좀더 nice 한 방법으로 인덱싱을 해보자. 바로 logstash 의 filter 기능이다. 그중 Grok filter 라는게 있는데 패턴을 적용하여 row data 를 필터링하는 기능이다. 조금 찾아보니 너무 고맙게도 아파치 필터 예제가 있어 수정하여 적용할수 있었다. http://grokconstructor.appspot.com/do/match?example=2
그래서 적용한 필터설정은 다음과 같다.
filter {
grok {
match => {
message => "%{IP:clientIp} (?:-|) (?:-|) \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:httpMethod} %{URIPATH:uri}%{GREEDYDATA}(?: HTTP/%{NUMBER})?|-)\" %{NUMBER:responseCode} (?:-|%{NUMBER})"
}
}
}
이렇게 하고 elasticsearch 에 인덱싱을 하면 키바나에서 다음과 같이 볼수 있다.
각 필드가 아닌 한줄로 인덱싱이 되어버린다.
Elasticsearch 에 인덱싱이 되긴 하는데 로그 한줄이 통째로 들어가 버린다. message라는 이름으로… 알고보니 현재 구조는 logstash가 kafka 앞 뒤에 있다보니 producer logstash 와 consumer logstash 의 codec이 맞아야 제대로 인덱싱이 될수 있었다.
먼저 access log에서 kafka 로 produce 하는 logstash 에서는 output 할때 codec 을 맞춰주고
output {
kafka {
bootstrap_servers => "123.1.2.3:9092,123.1.2.4:9092"
topic_id => "apache-log"
codec => json{}
}
}
kafka 에서 consume 하는 logstash 에서는 input 에서 codec 을 맞춰준다.
input {
kafka {
bootstrap_servers => "123.1.2.3:9092,123.1.2.4:9092"
topic_id => "apache-log"
codec => json{}
}
}
그렇게 되면 codec이 맞아 각 필드로 이쁘게 인덱싱을 할수 있게 되었다.
필요없는 uri는 제외하고 인덱싱할수 있을까?
/으로는 uri 라던지 /server-status같이 알고있지만 인덱싱은 하기 싫은 경우는 간단하게 아래처럼 if문으로 제외시킬수 있었다.(당연하게 보일진 모르겟지만 내겐 너무 생각보다 편하게 이슈를 해결할수 있어서 좋았다.)
output {
if [uri] =~ /.+/ and [uri] != "/server-status" {
kafka {
bootstrap_servers => "123.1.2.3:9092,123.1.2.4:9092"
topic_id => "apache-log"
codec => json{}
}
}
}
하나의 index로는 관리가 힘든데 나눌순 없을까?
사실 이 항목은 logstash에 해당하는 옵션이긴 하지만. 겸사겸사 적어본다. 이미 지난 로그는 지워야 할 상황이 온다. 이를테면 1년이 지났거나. 그럴경우 마지막 elasticsearch 로 output 하는 logstash 설정에서 다음과 같이 설정할수 있다.
output{
elasticsearch {
hosts => ["123.1.2.3:9200", "123.1.2.4:9200"]
index => "apache-log-%{+YYYY.MM}"
document_type => "apache"
}
}
이렇게 하고 apache 라는 템플릿을 지정해 놓으면 달이 바뀔때마다 자동으로 해당 템플릿에 맞추어 index가 만들어지게 되고, 원하는 달 전체의 데이터를 한번에 지울수 있는 장점이 있는것 같다.
이런 저런 삽질의 과정의 끝에는 달콤한 보상이 따르는것 같다.(항상 그러는건 아니지만..) 아래처럼 대시보드를 만들어 한눈에 apache 단에서의 request를 분석할수 있게 되었다. 물론 이보다 더 한것도 할수 있을것 같다.
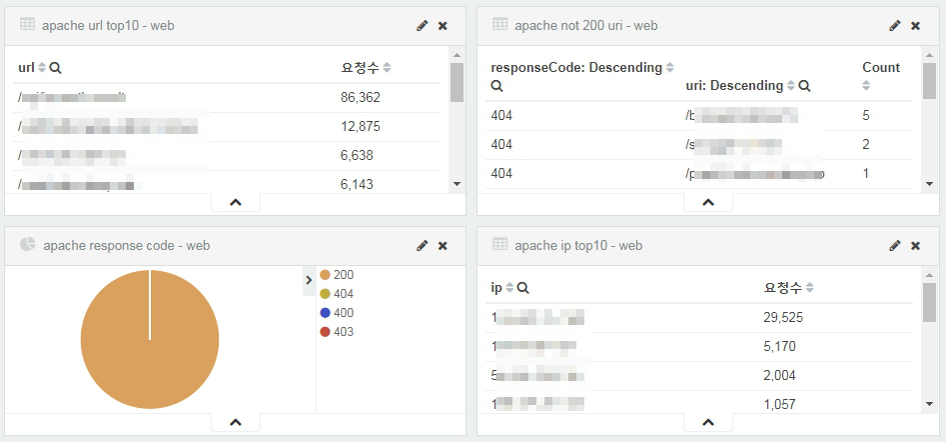
매번 새로운 기술을 습득할때마다 느끼는거지만, 고전 기술로 어렵게 어렵게 시간을 소비하며 구성하는 것보다 새로운 기술을 빨리 습득하고 삽질할 시간에 더 다양한 생각을 해보는게 좋은것 같다. 특히 이 Elasticsearch 는 설정 몇번만으로 이렇게 강력한(?) 구성을 만들수 있다는거에 너무 신기하면서도 감사하다.
자, 다음엔 또 어떤걸 해볼수 있을까!? 가즈아~
2018. 01. 26 추가
각 버전은 다음과 같다. (es를 어서 업그레이드 해야하는데...)
elasticsearch : 2.4.0
logstash : logstash-5.4.3
kafka : 0.11.0.0
apache : 2.2.x